on January 3, 2017
I’m sometimes asked if the number of CPU cores used by a query determines the number of tempdb files that the query can use.
Good news: even a single threaded query can use multiple tempdb data files.

First, tempdb is a tricksy place!
My first version of this post used a flawed methodology: I configured an instance of SQL Server 2016 with four equally sized, small tempdb files. I then tested a set of queries that qualify for parallelism alternately using 4 processors, and running them single threaded (using option maxdop 1 as a query hint).
I observed that the queries always made all four files grow.
However, in that first version of the post, I forgot that the default behavior in SQL Server 2016 is to grow all files in tempdb simultaneously when one grows. Basically, one small feature of SQL Server 2016 is that trace flag 1117 is always enabled by default for tempdb. Just because all the data files grew doesn’t mean they all got used!
(For more on tempdb behavior changes in SQL Server 2016, read Aaron Bertrand’s post here.)
Can we just turn off TF 1117 for tempdb?
For most databases, you can control whether all the files in a filegroup grow at once by changing a setting on the filegroup.
But not tempdb. If you run this command:
ALTER DATABASE tempdb MODIFY FILEGROUP [PRIMARY] AUTOGROW_SINGLE_FILE;
GO
You get the error:
Msg 5058, Level 16, State 12, Line 1 Option ‘AUTOGROW_SINGLE_FILE’ cannot be set in database ‘tempdb’.
Let’s use science. Otherwise known as Extended Events.
I admit: I didn’t do this in the first place because it was a bunch of work. The devil is in the detail with stuff like this. A lot of events seem like they’d work, but then you try to use them and either you don’t get the data you’d expect, or the trace generates such a massive amount of data that it’s hard to work with.
I used the sqlserver.file_read event and a histogram target
I love the histogram target because it doesn’t generate a huge file of data to confuse myself with. I set up my new test this way…
Extended Events trace for sql server.file_read
- Collect file paths (just to make it easy to see the data file names)
- filter on database_id=2 (tempdb)
- filter on session_id = 57 (the session I happened to be testing under)
- The histogram target was set to “bucket” file_read by each file path
I set up a bunch of queries in a batch, and for each query:
- Dumped everything out of memory (ran a checkpoint in tempdb and dbcc dropcleanbuffers)
- Ran a short waitfor in case the checkpoint took a bit of time
- Started the trace
- Ran the query
- Dumped the data from the histogram into a table
- Stopped the trace (this clears the histogram)
I ran the whole thing a couple of times to make sure I got consistent results. And I did!
Results: single threaded queries CAN use multiple tempdb data files
One of my queries does a large sort operation. Using maxdop 4 and maxdop 1, it still evenly used my tempdb data files.
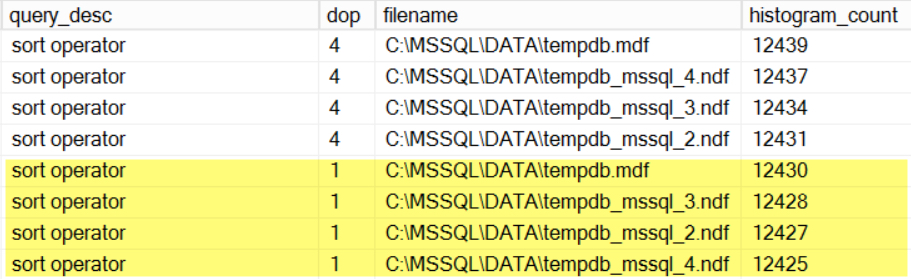
I saw similar patterns with a query using a merge join, a query using a lazy spool, and a query with a sort that was engineered to be under-estimated (and has a memory spill).
Results: queries may not use tempdb files in the same ways
As you might guess, things may not always get evenly accessed, even if you have evenly sized tempdb files. One of my queries did a select into a temp table. Although it used all four tempdb files whether or not it went parallel, there were more file_read events against the first tempdb file than against the other four.
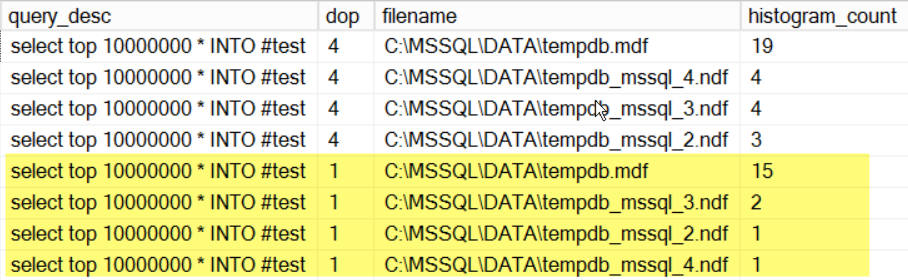
Could my methodology still have problems?
It’s possible. I haven’t used the sqlserver.file_read event much, or tested it super thoroughly. It seemed to give me consistent results.
So while it’s possible that I’ll suddenly realize that there’s a better way to measure this, I think at least my results are better than they were the first time I wrote this post!
 REGISTER
REGISTER