By Kendra Little on October 4, 2023
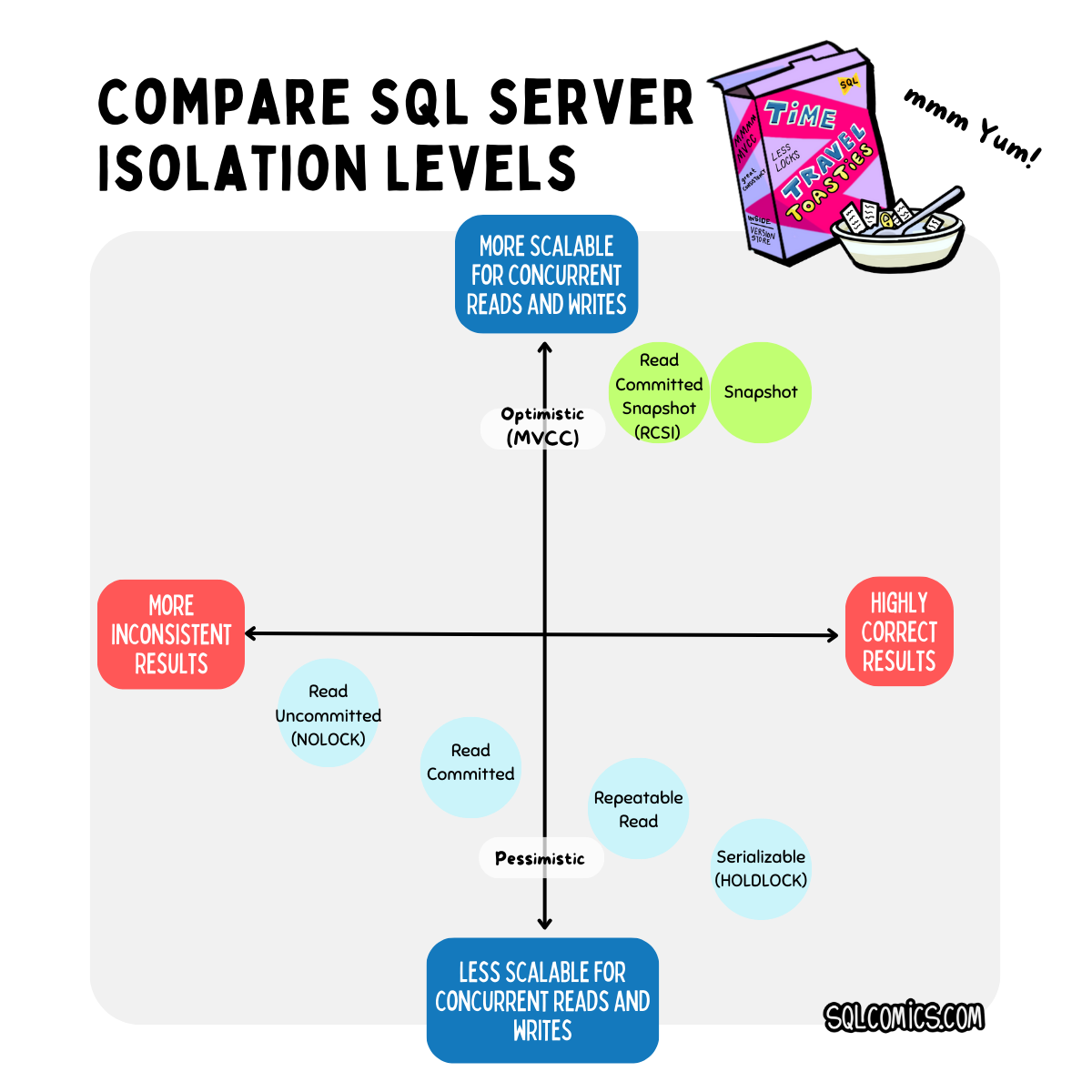
I shared an image on social media this week that describes how I feel about isolation levels in SQL Server (and its various flavors): the more concurrent sessions you have in a database reading and writing data at the same time, the more attractive it is to use version-based optimistic locking for scalability reasons.
There are two isolation levels in SQL Server that use optimistic locking for disk-based tables:
- Read Committed Snapshot Isolation (RCSI), which changes the implementation of the default Read Committed Isolation level and enables statement-based consistency.
- Snapshot Isolation, which provides high consistency for transactions (which often contain multiple statements). Snapshot Isolation also provides support for identifying update conflicts.
Many folks get pretty nervous about RCSI when they learn that certain timing effects can happen with data modifications that don’t happen under Read Committed. The irony is that RCSI does solve many OTHER timing risks in Read Committed, and overall is more consistent, so sticking with the pessimistic implementation of Read Committed is not a great solution, either.
“Race conditions” / timing issues under RCSI
Like many folks, I chat with various AI assistants these days. Although their claims require fact-checking, they help me understand concepts I’ve had a hard time getting my head around, as well as improve my wording on concepts I already DO understand. And unlike some forums, AI doesn’t chastise me that my question’s already been asked by user GoblinFeet1000 and will reword things without judgement until I catch on. (Aside: one example is the “Halloween problem,” which I now feel like I now understand the gist of! Future post, maybe.)
So I gave GitHub CoPilot the prompt: “what specific kinds of lost updates can happen under read committed snapshot isolation level in sql server”
Here’s my improved summary of RCSI’s timing issues after its help:
Under RCSI, readers generally don’t block writers, and writers don’t block readers. This means it allows transactions to read data that has been modified by other transactions but not yet committed. If one transaction reads data that another transaction has modified but not yet committed, and then attempts to update that data, the second transaction’s changes may be lost when the first transaction commits. This doesn’t happen with every type of modification, but some query plans for modification allow this risk.
But even re-worded, that explanation can make people pretty nervous to enable RCSI. (Note: if you’d like a technical post on timing issues under RCSI, Paul White has written a great one.)
RCSI fixes many timing issues you already have with Read Committed
Read Committed has plenty of its own timing issues, it’s just that most people figure they already have it and nobody is complaining, so it’s “comfortable” as the status quo.
Under Read Committed:
- Queries can miss rows entirely if they are modified in a way that relocates them in an index while a scan is ongoing.
- Similarly, rows can be counted twice for the same reason.
- Non-repeatable reads are allowed in transactions, so if you query something twice, it may have changed without explanation. (This can even happen within the a single query plan if it needs to read data twice.)
- Phantom reads are allowed in transactions, so if you read something twice something may have been added without explanation.
If good accuracy is needed for data in a highly concurrent situation, it’s not a great solution to stick with this!
According to ChatGPT, that would be like:
- Refusing a medicine that cures six ailments because it might cause one side effect.
- Not using a safety net while tightrope walking because it might snap, even though it would save you from multiple deadly falls.
- Not to carry an umbrella because it might get windy, even when the forecast predicts heavy rain.
- A traveler in the desert avoiding an oasis because of a rumored snake, while ignoring the clear water that could save them from thirst.
The way forward: protect your modifications
One essential thing is to recognize that protecting yourself against data inaccuracies with timing conditions is a requirement for using databases, no matter what isolation level you use.
For your data modifications, you can protect them from the risk of edge conditions by examining them and identifying what isolation level they actually need. Your queries that do modifications perhaps should run under repeatable read, serializable, or snapshot isolation level to avoid race conditions, depending on your patterns and your requirements. This can co-exist with RCSI– it doesn’t replace the need to sometimes use a different isolation level, it only changes how Read Committed is implemented.
If both scalability and data correctness matter, this is worth your time (even if you stick with pessimistic Read Committed as your default). Start by identifying the most frequent and most critical transactions that do modifications for your application, and identify what level of protection they need.
And if you decide that the risk of a few edge conditions is tolerable after looking at this, you might just enable RCSI like Michael J Swart’s team eventually decided to do.
 REGISTER
REGISTER