on November 10, 2016
SQL Server has two types of filtered indexes:
- The “classic” filtered nonclustered rowstore index, introduced in SQL Server 2008, available in all editions
- The newfangled filtered nonclustered columnstore index, introduced in SQL Server 2016, available in Enterprise Edition
These two filtered indexes are very different - and the SQL Server optimizer can use them very differently!
While classic filtered nonclustered rowstore indexes must reliably “cover” parts of the query to be used to the optimizer, filtered nonclustered columnstore indexes may be combined with other indexes to produce a plan returning a larger range of data.
This sounds a little weird. I’ll show you what I mean using the WideWorldImporters database.
Filtered nonclustered rowstore indexes (“Filtered Indexes”)
A filtered index is a nonclustered rowstore index with a “where” clause. This index contains only rows from Sales.Invoices which were last edited before February 1, 2013:
CREATE INDEX ix_nc_filter_LT
on Sales.Invoices (LastEditedWhen)
INCLUDE (CustomerID)
WHERE (LastEditedWhen < '2013-02-01');
GO
SQL Server may use this index if I run it for a query that also specifies LastEditedWhen < ‘2013-02-01’ (although possibly not if my query is parameterized and may be used for a date outside this range).
What if I am querying all CustomerIds, and I force SQL Server to use this index with a hint?
SELECT CustomerID
FROM Sales.Invoices WITH (INDEX (ix_nc_filter_LT));
GO
SQL Server could potentially pick up some of the rows from the filtered index, then find the rest of the rows in the base table and combine them. It’d be expensive, but it’s theoretically possible.
However, SQL Server can’t. Instead, I get this error:
Msg 8622, Level 16, State 1, Line 21 Query processor could not produce a query plan because of the hints defined in this query. Resubmit the query without specifying any hints and without using SET FORCEPLAN.
My query wants a larger range of data than is in my filtered rowstore index, and SQL Server won’t use the filtered rowstore index and then go find the rest of the data in another index. The optimizer just isn’t written to do this.
We’ve been used to this for years with filtered indexes. But filtered nonclustered columnstore indexes behave differently!
Filtered nonclustered columnstore indexes (“Filtered NCCI”)
Let’s create a filtered nonclustered columnstore index on the same table:
CREATE NONCLUSTERED COLUMNSTORE INDEX ix_ncci_filter_LT
on Sales.Invoices (LastEditedWhen, CustomerID)
WHERE (LastEditedWhen < '2013-02-01');
GO
I’m not saying this little demo table needs a nonclustered columnstore, I’m just reusing it for simplicity.
Now, I force SQL Server to use this index to get all the CustomerIDs:
SELECT CustomerID
FROM Sales.Invoices WITH (INDEX (ix_ncci_filter_LT));
GO
This time, the query doesn’t fail to get a plan! I get a plan, and I get all the 70,510 rows back. The execution plan looks like this:
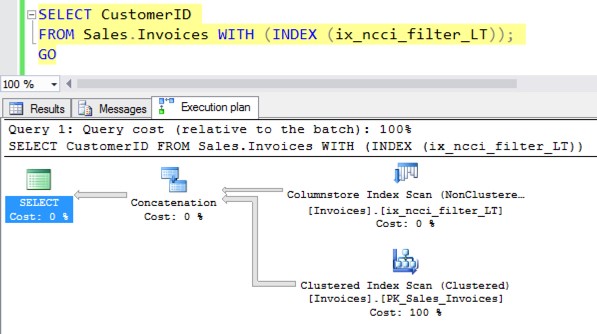
This isn’t an awesome plan. SQL Server scanned the columnstore index, then scanned the clustered index of the table to find the rows that weren’t in the columnstore index, then combined them. It did this because I forced it to use the columnstore hint.
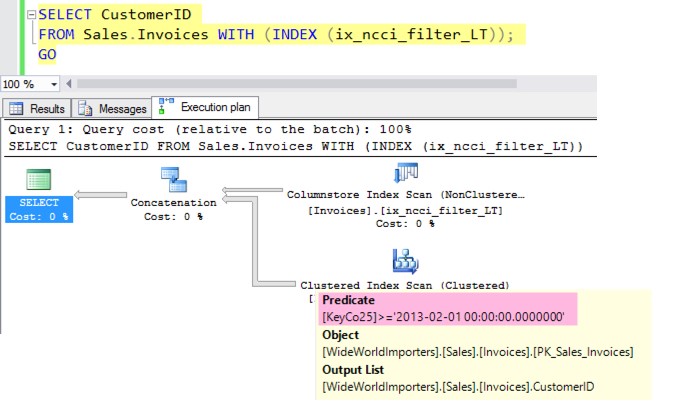
But SQL Server can make this plan. SQL was able to do this because it understands the filter in the nonclustered columnstore index. Hover over the clustered index scan in the plan, and you can see it figured out how to find the rest of the data in the clustered index:
Why are filtered nonclustered columnstore indexes smarter?
Columnstore indexes shine when it comes to scanning and aggregating lots of data. While nonclustered columnstore indexes are updatable in SQL Server 2016, it’s expensive to maintain them.
SQL Server is smarter about optimizing plans with filtered nonclustered columnstore indexes so you can design your filter so that “cold” data which is unlikely to be modified is in the columnstore index. This makes it cheaper to maintain. The optimizer has the ability to use the filtered NCCI and combine it with other indexes behind the scenes.
You do want to be careful with your filter and make sure that it doesn’t have to do a clustered index scan every time it’s going to do this trick, of course!
Read more about this feature on the SQL Server database engine blog in Sunil Agarwal’s post, “Real-Time Operational Analytics: Filtered nonclustered columnstore index (NCCI).”
 REGISTER
REGISTER