on September 22, 2016
Should you always index your foreign keys? What if you index them, and then the index never gets used?
Dear SQL DBA,
We recently had a SQL Server performance assessment. It remarked on two things that made me think:
1 ) tables with foreign keys but missing supporting index 2 ) tables with indexes that are not used
But in our case the remark in Case 2 was on a index that supports a foreign key!
Curtain down!
Now to my question, in which cases should you as a rule create indexes to support a foreign key?
Regards, The Indexer Who Can’t Win
LOL. I love this one!
Clearly, the solution is to write some meaningless queries that use every unused foreign key indexes, right? :D
Quick background - what’s a foreign key?
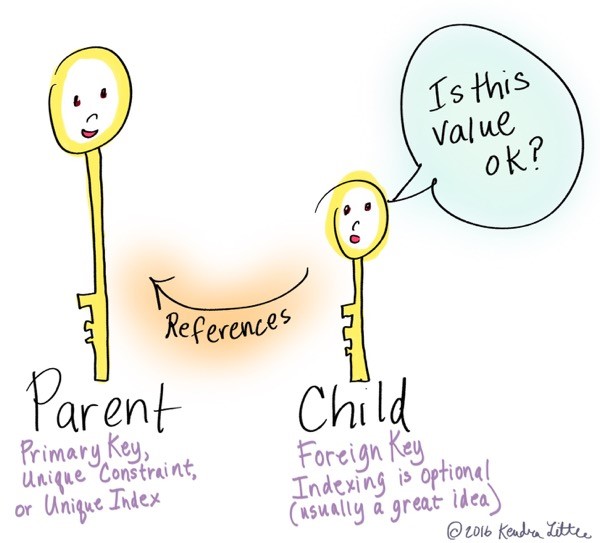
Foreign keys are a great way to make sure you have valid data in a relational database.
I think of this in terms of parents and children. For example, let’s say I have two tables: dbo.FirstName, and dbo.Students.
The dbo.FirstName table is the parent table. It has two columns, FirstNameId, and FirstName. This parent contains the valid, unique list of FirstNames. The FirstNameId column is defined as a Primary Key column.
The dbo.Students table is the child table. It has many columns. FirstNameId is one of the columns.
I can create a Foreign Key constraint on the child dbo.Students.FirstNameId that references the parent, dbo.FirstNames.FirstNameId.
This means that whenever I insert a row into dbo.Students, SQL Server will check and make sure that the FirstNameId I use is a valid row in the parent table, dbo.FirstNames.
You can get creative with foreign keys:
- The parent and child key columns can be in the same table
- You can have multiple columns in your foreign key (the number of columns and data types have to match between parent and child)
- The parent key can even be a unique index instead of a primary key or unique constraint
It’s a good practice to index your foreign keys
To be clear, you don’t have a choice about indexing on the ‘parent’ side of the foreign key. The referenced parent key column(s) has to have an index. (Primary keys and unique constraints are all backed by an index.)
You have a choice about whether to index the columns in the child table - in my example, on dbo.Students.FirstNameId.
I generally do index the child keys, because it’s very common for queries to join between the parent and child columns of a foreign key So there’s a good likelihood you’re going to need an index there.
Erin Stellato wrote a great post on SQLPerformance.com with example code showing why indexing a foreign key can make a big performance difference. It’s called “The Benefits of Indexing Foreign Keys”.
There will be some times when you want to make an exception. (More on this soon.)
What about those ‘unused index’ warnings?

Whomever ran your performance assessment didn’t have time to look at this very deeply – or if they did, they didn’t explain it in detail. I can’t really criticize them too much, I’ve had egg on my own face before.
There’s a couple of possibilities about why indexes on your foreign keys might not be used:
- No queries are being run that join between the parent and child table.
- Queries are being run, but they don’t like the index because it doesn’t ‘cover’ the query – so they’re doing something else. They could be scanning the base table or using a near-duplicate index.
- If there is another index that leads on the same keys that is pulling all the weight and covers the foreign key better, the narrow index keyed only on the foreign key columns isn’t adding value.
I would look for the “lesser evil”.
To check if an unused index is really a problem, ask:
- Is the unused index so large that it takes up significant room in the data file / backups / restores?
- Does the table have such a high rate of modifications that the index may be a performance problem?
If either of these are a big concern, I’d consider dropping the index on the foreign keys.
However, I would want to monitor it for some time to make sure that there isn’t a workload that really cares about that index which just hasn’t run in a while.
- Index usage gets reset when the database comes online
- In many versions of SQL Server, index rebuilds also reset this information. See my post “What Resets Index Usage Stats and Missing Index DMVs?” for details.
When might you want to not use a simple index on foreign key columns?
There’s always an exception, right?
Here are some examples I can think of when I might not want a simple index on a child key:
- The foreign key index might help performance significantly if it’s widened to “cover” critical queries. In this case, adding additional key and/or included columns may improve query performance (Fairly common)
- For tables with very high modifications rates which are performance sensitive, when I know for sure I don’t need to index the foreign keys, they just add overhead and don’t help. You need to be sure you don’t need the foreign key index, or you could run into a major blocking problem because they’re missing, though. (Edge case)
- When the data in the foreign key columns is very non-selective and it’s a super narrow table, indexing the foreign key may not make a huge performance difference. (Edge case)
I think SQL Server should index foreign keys automatically
I actually think it would be a nice feature for SQL Server to index foreign key columns automatically, as long as it let you specify not to do so, and also let you alter/drop the indexes later.
There’s a fun discussion of this on Greg Low’s blog from 2008 in his post, “Indexing Foreign Keys - Should SQL Server Do that Automatically?”
I feel like this is a “nice to have” feature, but I don’t feel strongly about the SQL Server product team spending time on it. They’ve got other features that I’d like to have more, because in this case I think other features help compensate a bit.
SQL Server’s “missing index” feature isn’t perfect, but it’s pretty darn good at complaining. If you forget to index a foreign key that’s critical to queries or if the index gets dropped, SQL Server is pretty likely to start asking for an index.
So if you’re looking at your missing index warnings, you’re likely to figure out that an index on the foreign key column can speed up your queries (maybe without even realizing it’s related to a foreign key).
I do recommend handling the missing index feature carefully, like it’s a small child who really wants candy in the grocery store checkout line. But that’s a story for another day.
Summing it all up
So, which is Worse: an Unused Index, or an Un-Indexed Foreign Key? Usually an un-indexed foreign key is worse.
 REGISTER
REGISTER