on February 4, 2016
Sometimes when SQL Server gets slow, developers and DBAs find that the problem is blocking. After lots of work to identify the query or queries which are the blockers, frequently one idea is to add ROWLOCK hints to the queries to solve the problem or to disable PAGE locks on the table. This often backfires - here’s why.

The Theory: ROWLOCK Makes Locks More Granular
The idea behind the change is that by forcing SQL Server to take out row locks instead of page locks, each individual lock will be smaller. If locks are smaller, queries will be less likely to block one another.
How It’s Implemented: Hints and ALTER INDEX SET ALLOW_PAGE_LOCKS=OFF
By default, the SQL Server engine will select row or page based locks based on what it thinks is best. You can coerce the database engine into using row based locking in two ways: TSQL hints, or by disallowing page locks on an index.
The TSQL hint is a table variant. If you have joins, you can specify this per table, like this:
SELECT fnby.Gender, fnby.NameCount, fnby.ReportYear
FROM agg.FirstNameByYear AS fnby WITH (ROWLOCK)
JOIN ref.FirstName AS fn on fnby.FirstNameId=fn.FirstNameId
WHERE fn.FirstName='Shakira';
GO
If you can’t change the query, the TSQL hint can be applied using a plan guide. (That is, if you can get the plan guide to work. They’re squirrely.)
The ALTER INDEX variant looks like this, and impacts any query using that index:
ALTER INDEX pk_aggFirstNameByYear ON agg.FirstNameByYear SET ( ALLOW_PAGE_LOCKS = OFF );
GO
By disallowing page level locks, the only options left are ROW, TABLE, and perhaps partition level (more on that later).
One Problem: Forcing ROWLOCK Increases CPU Time and Duration if a Page Lock was Preferred
Here’s an Extended Events trace showing the difference in CPU Time and Duration for a SELECT query. The top 10 results are when the database engine chose the locking level (it selected page). The second 10 results have a ROWLOCK hint forcing row level locks against the agg.FirstNameByYear table.
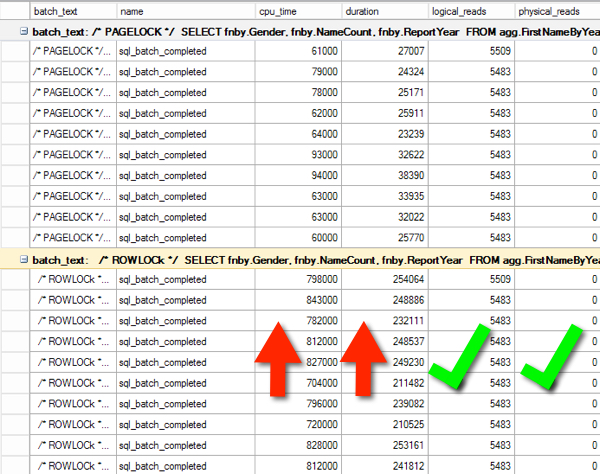
Note that the logical reads are the exact same and neither query is doing physical reads (the execution plans are the same– the optimizer doesn’t care what locks you are using). The queries were run with SET STATISTICS IO,TIME OFF and Execution Plans turned off, just to reduce influencing factors on duration and CPU.
The database engine is simply having to do more work here. Locking the pages in the clustered index is less work than locking each of the 1,825,433 rows.
Even though our locks are more granular, making queries run longer by taking out individual locks will typically lead to more blocking down the road.
If you’d like to run the test yourself against the BabbyNames database, here’s the code.
/* PAGELOCK */
SELECT fnby.Gender, fnby.NameCount, fnby.ReportYear
FROM agg.FirstNameByYear AS fnby
JOIN ref.FirstName AS fn on fnby.FirstNameId=fn.FirstNameId
WHERE fn.FirstName='Shakira';
GO 10
/* ROWLOCK */
SELECT fnby.Gender, fnby.NameCount, fnby.ReportYear
FROM agg.FirstNameByYear AS fnby WITH (ROWLOCK)
JOIN ref.FirstName AS fn on fnby.FirstNameId=fn.FirstNameId
WHERE fn.FirstName='Shakira';
GO
Another Problem: Lock Escalation
The SQL Server Engine is a little worried about managing lots of little locks. Those locks take up memory. When you hit 5,000 locks on a single table you pass the internal lock escalation threshold and the database engine will attempt to replace your little bitty locks with one larger table level lock.
That sounds great, except for this:
- Lock escalation is from row to table or page to table (never from row to page)
- If your query is making a modification, the escalation will be to an exclusive lock on the whole table
It’s quite possible to turn a periodic small blocking problem with page locks into a sporadic big blocking problem due to lock escalation.
Here’s an example against the SQLIndexWorkbook database. We’re updating NameCount for a given report year. Here’s our query starting out… (Yep, we’re setting NameCount to itself. It’ll still take out the locks.)
UPDATE agg.FirstNameByYear
SET NameCount=NameCount
WHERE Gender='M';
SQL Server figured out that it could run this query with an intent exclusive (IX) lock on agg.FirstNameByYear and 4961 exclusive (X) PAGE locks on the clustered primary key. That’s not awesome - it’s most of the table.
But if I change the query to force ROWLOCKS like this, the problem does not get better.
UPDATE agg.FirstNameByYear
WITH (ROWLOCK)
SET NameCount=NameCount
WHERE Gender='M';
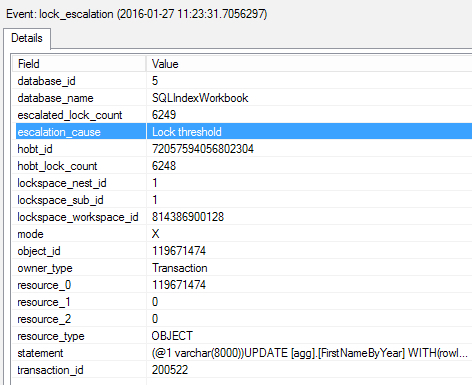
Now I end up with SQL Server attempting to escalate locks after it passes 5,000 row locks, retrying the operation every 1,250 new locks. Here’s an example of Extended Events catching a lock_escalation event for this query, which promoted the locks to an exclusive table lock:
Workaround: Disable (or Change) Lock Escalation
You can control lock escalation at the table level using the ALTER TABLE command. In our example, we can do this:
ALTER TABLE agg.FirstNameByYear SET ( LOCK_ESCALATION = DISABLE);
GO
Now, our UPDATE query with the ROWLOCK hint gets 743,750 exclusive (X) KEY locks, 4,961 intent-exclusive (IX) PAGE locks, and one intent exclusive (IX) lock on the object.
In some cases, disabling lock escalation and forcing row locks may work well, depending on the access patterns of your table and how much is being locked. Memory is needed to maintain locks, but the memory for lock structures is very small compared with memory for buffer pool and other components on modern SQL Servers. If you’re concerned about memory use for locks, you can baseline it and test using performance counters:
SELECT object_name, counter_name,
cntr_value/1024. as memory_mb
FROM sys.dm_os_performance_counters
WHERE counter_name = 'Lock Memory (KB)';
GO
That being said, I would only disable lock escalation when needed in a controlled setting, when there weren’t better options.
Partition Level Escalation
If you’re using partitioned tables, lock escalation still defaults to TABLE. However, you can change lock escalation so it goes from ROW -> PARTITION or from PAGE -> PARTITION.
That’s done by running:
ALTER TABLE agg.FirstNameByYear SET ( LOCK_ESCALATION = AUTO);
GO
I know, you’d think ‘AUTO’ would be the default. It’s not, because you might run into partition level deadlocks. If you have large partitioned tables and lock escalation is an issue, partition level escalation is worth testing.
Workaround: Tune the TSQL
In our example, the obvious question is why we’re even running this query, since it’s updating a value to itself and not performing a meaningful change. If it was doing something meaningful, it’d be desirable to work on the TSQL to have it perform the modifications in smaller, more controlled batches. This minimizes the lock footprint.
This is typically doable for batch update jobs and behind the scenes processing.
Workaround: Use Optimistic Locking (Snapshot or Read Committed Snapshot) for SELECT Queries
One of my favorite tools to fight blocking is isolation levels. Frequently the blocked queries are predominantly read-only– they’re SELECT queries. Why should those queries have to wait for the update to finish?
SQL Server’s SNAPSHOT and READ COMMITTED SNAPSHOT isolation levels are great for these queries. They can get consistent, valid data regardless of whether a modification is running by using row versioning in tempdb. This is a longer term change, not a quick fix. For transactional OLTP databases, optimistic locking is one of the best tools out there.
Takeaways: Use ROWLOCK Hints Cautiously
I’m not against ROWLOCK hints, I’ve just seen them backfire. If you choose to force row locking as part of your solution, check to make sure it’s not slowing down your queries and keep a close eye on blocking and lock escalation on your tables.
 REGISTER
REGISTER