on November 17, 2015
Working with table partitioning can be puzzling. Table partitioning isn’t always a slam dunk for performance: heavy testing is needed. But even getting started with the testing can be a bit tricky!
Here’s a (relatively) simple example that walks you through setting up a partitioned table, running a query, and checking if it was able to get partition elimination.
In this post we’ll step through:
- How to set up the table partitioning example yourself
- How to examine an actual execution plan to see partition elimination and which are accessed. Spoiler: you can see exactly which partitions were used / eliminated in an an actual execution plan.
- Limits of the information in cached execution plans, and how this is related to plan-reuse
- A wrap-up summarizing facts we prove along the way. (Short on time? Scroll to the bottom!)
Set up table partitioning for hands-on experience
Get the Sample Database
We’re using the FactOnlineSales table in Microsoft’s free ContosoRetailDW sample database. The table isn’t very large. Checking it with this query:
SELECT
index_id,
row_count,
reserved_page_count*8./1024. as reserved_mb
FROM sys.dm_db_partition_stats
WHERE object_id=OBJECT_ID('FactOnlineSales');
GO
Here’s the results:
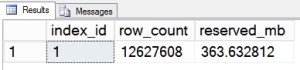
The table has 12.6 million rows and only takes up 363 MB. That’s really not very large. We probably wouldn’t partition this table in the real world, and if we did we would probably use a much more sophisticated partition scheme than we’re using below.
But this post is just about grasping concepts, so we’re going to keep it super-simple. We’re going to partition this large table by year.
Create the Partition Function
Your partition function is an algorithm. It defines the intervals you’re going to partition something on. When we create this function, we aren’t partitioning anything yet – we’re just laying the groundwork.
CREATE PARTITION FUNCTION pf_years ( datetime )
AS RANGE RIGHT
FOR VALUES ('2006-01-01', '2007-01-01', '2008-01-01', '2009-01-01', '2010-01-01');
GO
Unpacking this a bit…
DATETIME data type: I haven’t said what column (or even table) I’m partitioning yet – that comes later. But I did have to pick the data type of the columns that can use this partitioning scheme. I’ll be partitioning FactOnlineSales on the DateKey column, and it’s an old DateTime type.
RANGE RIGHT: You can pick range left or range right when defining a partition function. By picking range right, I’m saying that each boundary point I listed here (the dates) will “go with” the columns on the partition to the right.
This means that the boundary point ‘2007-01-01’ will be included in the partition with the dates above it. That’s the rest of the dates for 2007.
Usually with date related boundary points, you want RANGE RIGHT. (We don’t usually want the first instant of the month, day, or year to be with the prior year’s data.)
VALUES: Why doesn’t the partition function go to present day? Well, the Contoso team apparently decided to use some other database after the end of 2009. That’s the lastest data we have.
Create the Partition Scheme and Map it to the Function
A partition scheme tells SQL Server where to physically place the partitions mapped out by the partition function. Let’s create that now:
CREATE PARTITION SCHEME ps_years
AS PARTITION pf_years
ALL TO ([PRIMARY])
GO
Let’s talk about “ALL TO ([PRIMARY])". I’ve done something kind of awful here. I told SQL Server to put all the partitions in my primary filegroup.
You don’t always have to use a fleet of different filegroups on a partitioned table, but typically partitioned tables are quite large. Dumping everything in your primary filegroup doesn’t give you very many options for a restore sequence.
But we’re keeping it simple.
Partition the Table on the Partition Scheme
This is where it gets real. Everything up to this point has been metadata only.
Currently, the FactSales table has a clustered Primary Key on the SalesKey column and no nonclustered indexes. We’re going to partition the table by the DateKey column. The first step is to drop the clustered PK, like this:
ALTER TABLE dbo.FactSales
DROP CONSTRAINT PK_FactSales_SalesKey;
GO
Now partition the table by creating a unique clustered index on the partition scheme, like this:
CREATE UNIQUE CLUSTERED INDEX cx_FactSales
on dbo.FactSales (SalesKey, DateKey)
ON [ps_years] (DateKey)
GO
We made a couple of important changes. The table used to have a clustered PK on SalesKey, but we replaced this with a unique clustered index on TWO columns: SalesKey, DateKey. There’s a reason for this: if we’re partitioning on DateKey and we try to create a unique clustered index on just SalesKey, I’ll get this message:
Msg 1908, Level 16, State 1, Line 31 Column ‘DateKey’ is partitioning column of the index ‘cx_FactSales’. Partition columns for a unique index must be a subset of the index key.
DateKey is elbowing its way into that clustered index, whether I like it or not.
All right, now that we have a partitioned table, we can run some queries and see if we get partition elimination!
Query the Partitioned Table and Look at the Actual Execution Plan
Our example query is this stored procedure:
CREATE PROCEDURE dbo.count_rows_by_date_range
@s datetime,
@e datetime
AS
SELECT COUNT(*)
FROM dbo.FactSales
WHERE DateKey between @s and @e;
GO
exec dbo.count_rows_by_date_range '2008-01-01', '2008-01-02';
GO
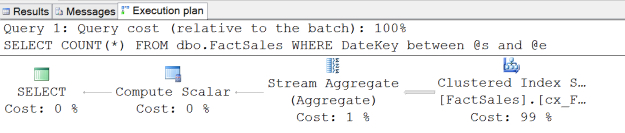
If we run that call to dbo.count_rows_by_date_range with “Actual Execution Plans” enabled, we get the following graphic execution plan:
 ]
]
It’s a clustered index scan, but don’t jump to conclusions.
We have a clustered index scan operator on the fact sales table. That looks like it’s scanning the whole thing– but wait, we might be getting partition elimination! This is an actual execution plan, so we can check.
Hovering over the Clustered Index Scan operator on Fact Sales, a tooltip appears!
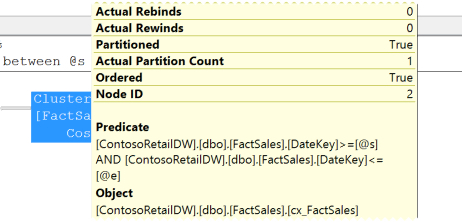
Partitioned = True![/caption]*
It knows the FactSales table is partitioned, and “Actual Partition Count” is 1. That’s telling us that it only accessed a single partition. But which partition?
To tell that, we need to right click on the Clustered Index Scan operator and select “properties”:
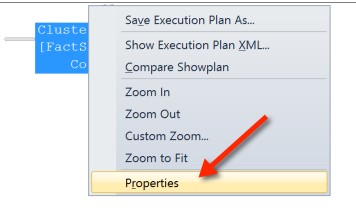
Decoding this: The clustered index scan accessed only one partition. This was partition #4.
Let’s re-run our query to make it access more than one partition! We’re partitioning by year, so this should touch two partitions:
exec dbo.count_rows_by_date_range '2007-12-31', '2008-01-02';
GO
Running this query with actual execution plans on, right clicking the Clustered Index Scan, and looking at properties, this time we see it accessing two partitions, partition #3 and partition #4:
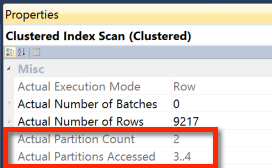 ]
]
Just because you see “Clustered Index Scan” doesn’t mean you didn’t get partition elimination. However, even if you did get partition elimination, it may have needed to read from multiple partitions.
Can You See Partition Elimination in the Cached Execution Plan?
So far we’ve been looking at Actual Execution plans, where I’ve run the query in my session. What if this code was being run by my application, and I wanted to check if it was getting partition elimination?
If the execution plan was cached, I could find information on its execution and cached plan with this query:
SELECT
eqs.execution_count,
CAST((1.)*eqs.total_worker_time/eqs.execution_count AS NUMERIC(10,1)) AS avg_worker_time,
eqs.last_worker_time,
CAST((1.)*eqs.total_logical_reads/eqs.execution_count AS NUMERIC(10,1)) AS avg_logical_reads,
eqs.last_logical_reads,
(SELECT TOP 1 SUBSTRING(est.text,statement_start_offset / 2+1 ,
((CASE WHEN statement_end_offset = -1
THEN (LEN(CONVERT(nvarchar(max),est.text)) * 2)
ELSE statement_end_offset END)
- statement_start_offset) / 2+1))
AS sql_statement,
qp.query_plan
FROM sys.dm_exec_query_stats AS eqs
CROSS APPLY sys.dm_exec_sql_text (eqs.sql_handle) AS est
JOIN sys.dm_exec_cached_plans cp on
eqs.plan_handle=cp.plan_handle
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle) AS qp
WHERE est.text like '%FROM dbo.FactSales%'
OPTION (RECOMPILE);
GO
Here’s the results for our query:

Sys.dm_exec_query_stats has great info! The difference between the average logical reads and the last logical reads shows us that sometimes this query reads more than others– that’s because the first time we ran it, it had to scan one partition. The second time we ran it, it had to query two. If it was always scanning the whole table, we’d have the same number of logical reads for the average and the last.
We can also see that the same execution plan was reused for both queries. Clicking on the cached query plan to open it up, we see something similar… but it doesn’t have all the same info.
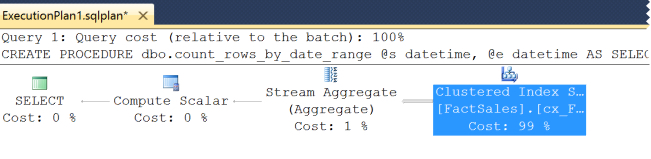
The clustered index scan is the same…
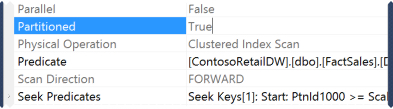
But in the properties we can only see that it knows the table is partitioned.
The cached execution plan does not contain information on the number of partitions accessed or which ones were accessed. We can only see that in the Actual Execution plan.
A recap of what we saw
Here’s a quick rundown of what we did and saw:
- We partitioned the FactSales table by creating a partition function and partition scheme, then put a unique Clustered Index on the SalesKey and DateKey columns
- When we ran our query with actual execution plans enabled, we could see how many partitions were accessed and the partition number
- When we looked at the cached execution plan, we could see that the same execution plan was able to be re-used across multiple runs, even though:
- It was a parameterized stored procedure
- The query accessed a different number of partitions on each run (one partition on the first run, two partitions on the second run)
- The cached execution plan did not contain the number of partitions accessed. (Makes sense, given the plan re-use!)
- We could see the average and last number of logical reads from sys.dm_exec_query_stats, which could give us a clue as to whether partition elimination was occurring
Super simple, right? :)
If you liked this post and you’re ready for something more challenging, head on over to Paul White’s blog and read about a time when partition elimination didn’t work.
 REGISTER
REGISTER