on February 2, 2018
I recently got a great question: if I order by a column where all rows in that column have the same value, will SQL Server then order the results by the clustered index key?
![]()
The short answer: SQL Server only guarantees that results are ordered per the columns you specify in an ORDER BY clause
There is no “default” ordering that a query will fall back on outside of an ORDER BY clause.
- Results may come back in the order of the clustered index, or they may not
- Even if results come back in the order of the clustered index on one run of the query, they may not come back in the same order if you run it again
If you need results to come back in a specific order, you must be explicit about it in the ORDER BY clause of the query.
Bonus details: ORDER BY is special inside view definitions. As Books Online explains:
The ORDER BY clause is used only to determine the rows that are returned by the TOP or OFFSET clause in the view definition. The ORDER BY clause does not guarantee ordered results when the view is queried, unless ORDER BY is also specified in the query itself.
The question wasn’t about views, though, it was about queries.
Let’s prove it! Bring on the demo
The question came with some demo code. For fun, I adapted the code to use 1 million results in the demo table, which introduces the extra factor of parallelism on my test instance. (I have the Cost Threshold for Parallelism setting at the default of 5, which is super low– I have it that way just for demo purposes.)
If you’d like to play along, the sample code for this is in a Gist, which I’ve also included at the bottom of this post.
Our table
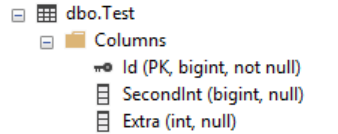
Our demo table has a simple schema: there are three columns. The column named Id is a clustered primary key.
If we do a simple unordered SELECT statement from the table, the results look like SQL Server will default to returning the rows to us in an order defined by the clustered primary key.
However, that just happened to be what we got this time. We can’t rely on that in other queries, as we’re going to see.
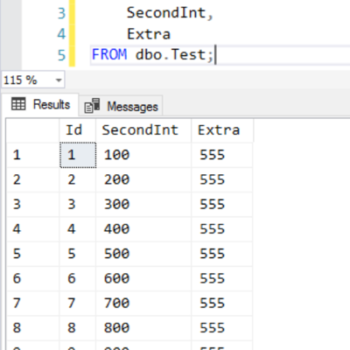
Query 1 - Order by Extra, DESC
Notice in our sample data that the “Extra” column is an integer which always has the value 555. That is true for every row in the table.
What happens if we order by “Extra”? All the rows have the same value. Will SQL Server “fall back” on ordering by the Clustered Index– which is the only index it has?
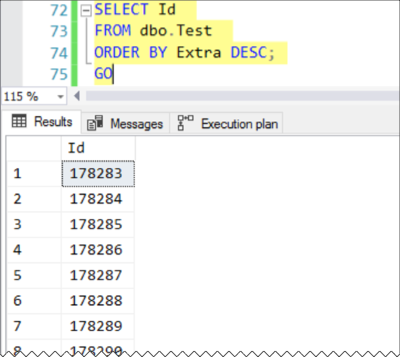
Nope! Id = 1 is nowhere in sight.
And to make this really fun, run the exact same query a second time. Here’s what I got on my second run:
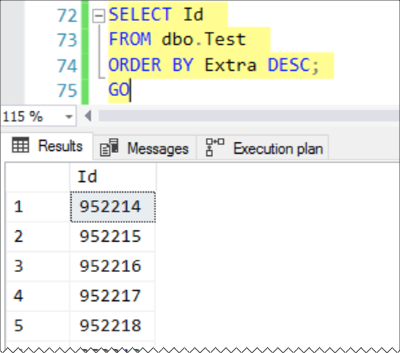 ]
]
The ordering is different. None of the data has changed in the table, I just happened to get the rows back in a different order.
Let’s look into the execution plan
Here’s the plan I got for Query 1:
 ]
]
This query got parallelism on my test instance. It did:
- An unordered scan on the clustered index, separating the work cross multiple threads
- A sort on the Extra column (no other columns to sort by)
- A re-gathering of the threads
SQL Server is trying to get the results back to me as quickly as possible. It is only sorting things by the Extra column, and since that value is the same for all rows in this case, I can get rows back in whatever order happens first on that run.
Query 2 - What if we add in TOP 2?
For query 2, you’ll get back two rows. But because the only column specified in the ORDER BY is Extra (and all rows for Extra have the same value), if you run the query repeatedly you will likely see that you don’t always get the same two rows back (and they aren’t the rows for Id = 1 and Id = 2).
The TOP does change the execution plan, in this case.
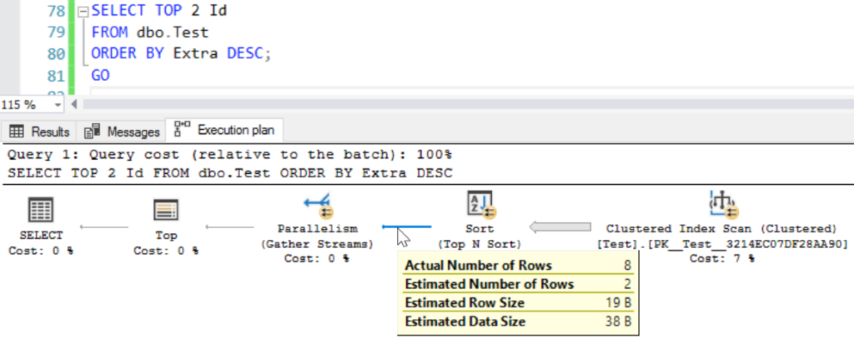
Why do I have both a Top N Sort and then another Top?
Well, I have 4 cores on this instance, and the query is going parallel. What it’s doing is scanning the clustered index with 4 cores. For each of those cores, it gets the top 2 rows (based on Extra), then it pulls those 8 rows together and does a final TOP on them.
Since I’m only ordering by the column Extra, SQL Server doesn’t consider anything else again.
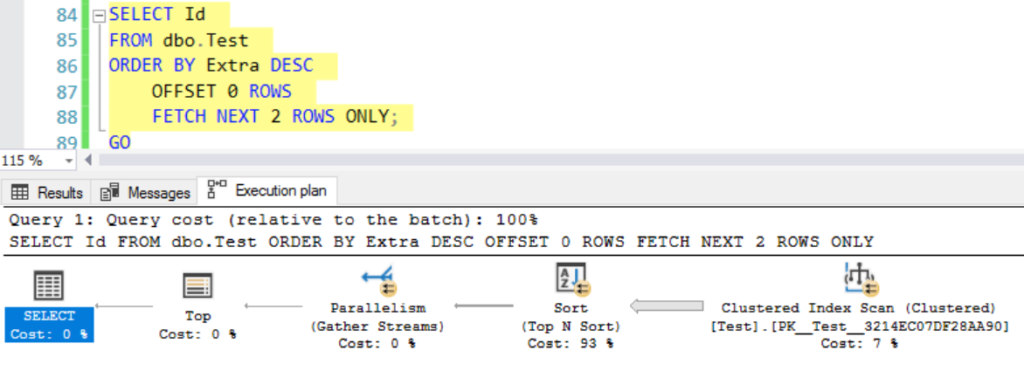
Query 3 - OFFSET and FETCH
Query gets rid of TOP, and instead tries out OFFSET and FETCH.
Again, we get two rows back (because of the FETCH limitation), but they can be any two rows in the table since our ORDER BY column is essentially meaningless (all rows have the same value).
I get the exact same plan as I got for the TOP query in this case– same costs, same estimates, everything.
 ]
]
Query 4 - OFFSET and FETCH with local variables
Query 4 gets a little fancier – instead of using literal values for offset and fetch, it introduces local variables. Again, we get two rows back, but they can be any two rows in the table.
But the execution plan is different:
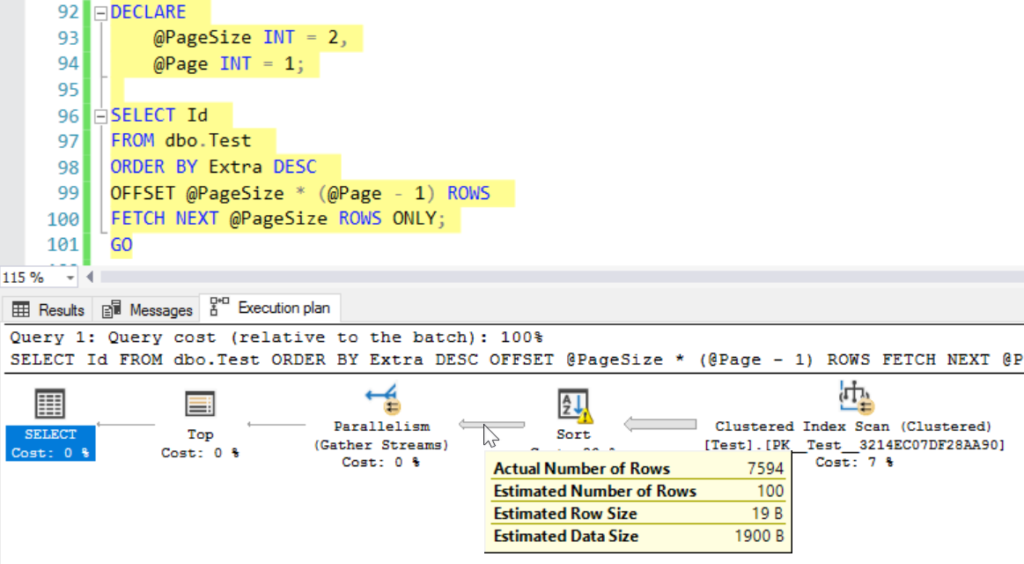
We don’t have an estimate of 8 rows anymore– we have an estimate of 100.
That’s because we used a local variable, @PageSize. Local variables anonymize their contents, unless you use a RECOMPILE hint. When SQL Server optimized this query, it wasn’t sure how many rows it needed to fetch, so it just guessed. If you set @PageSize = 200000, you’ll get the exact same estimates and plan for this query.
Is it only parallelism that can cause this?
Nope, there are other things, such as allocation order scans, which might change up the order, too.
tldr: When it comes to ordering of results, SQL Server does what you ask in an ORDER BY– and no more!
Except in the case of ORDER BY inside a view, when it actually does less. (Details back at the top of the post.)
If you’re not convinced after all this, or just need a laugh, read Michael Swart’s impressions of bloggers answering a similar question.