on July 5, 2017
Working with maintenance plans is supposed to be easy, but I find it to be quite difficult.

In part, this is because they can often be buggy. To write this post today, I had to go back and install SSMS 16.5, because I wasn’t able to configure logging or change some aspects about my test maintenance plan in SSMS 17. (I use case sensitive instances, and this bug also impacts things like the maintenance plan log dialog box.)
And in part this is because the documentation for maintenance plans doesn’t tend to be as clear as the documentation for TSQL commands. So in the interest of saving other folks time, I wanted to share what I learned about the Rebuild Index Task, Reorganize Index Task, and Update Statistics Task in SQL Server 2016.
You don’t have to use maintenance plans, but lots of people still do
If you already are happily doing your index and statistics maintenance with Ola Hallengren’s free scripts, Minion Reindex, or a different solution that works well for you - I’m not writing this post to change your mind! Not at all. Go forth and be happy.
If you’re using maintenance plans because you’re not comfortable with other scripts, or your management has a mandate that you only use the built-in tools, then this post is for you.
And just to be clear, I am writing this post to give you reasons to not use maintenance plans, and to go try out one of those scripts. I’m going to step through the improvements added into maintenance plans in SQL Server 2016, and explain why they still have notable flaws.
To be honest, I don’t blame Microsoft for those flaws: there are such great scripts for this generated by the community that I don’t know why they’d put much effort into making index and statistics maintenance perfect in the product. I wouldn’t! If customers want something more flexible, there are multiple free options out there which are highly configurable. Personally, I’m happier if Microsoft’s developer time goes into more cool features inside the products where community scripts can’t help out.
So please don’t read this post as complaints about the product! Really, I just want to encourage you to use cool community scripts.
The index maintenance tasks are historically very inefficient in SQL Server
For older versions of SQL Server (the ones most people use still, since most folks are slow to upgrade), maintenance plans offer a “defragment everything, every time” approach to index maintenance:
- The Reorganize Index task reorganizes all indexes, regardless of fragmentation level
- The Rebuild Index task similarly bulldozes through everything and rebuilds every index, without checking fragmentation
There’s not a lot of guidance in the maintenance plan designer, so it’s not uncommon for people to rebuild every index, and then reorganize it afterwards: defragment one way, then defragment another.
Although this is a lot of wasted effort, if you have small databases and a large maintenance window, it may not be a big problem.
But the bigger your data gets, the longer it takes. And more and more often, people like to be able to work nights and weekends, and they expect performance from the database whenever they happen to be active. That maintenance window is shrinking.
SQL Server 2016 added some features to the Rebuild Index Task
We’ve had a very handy dynamic management view in SQL Server to check for fragmentation since SQL Server 2005, but maintenance plans didn’t give you a built-in way to use it until SQL Server 2016. Better late than never, maybe?
Here’s the updated Index Rebuild task. New stuff is highlighted in yellow:
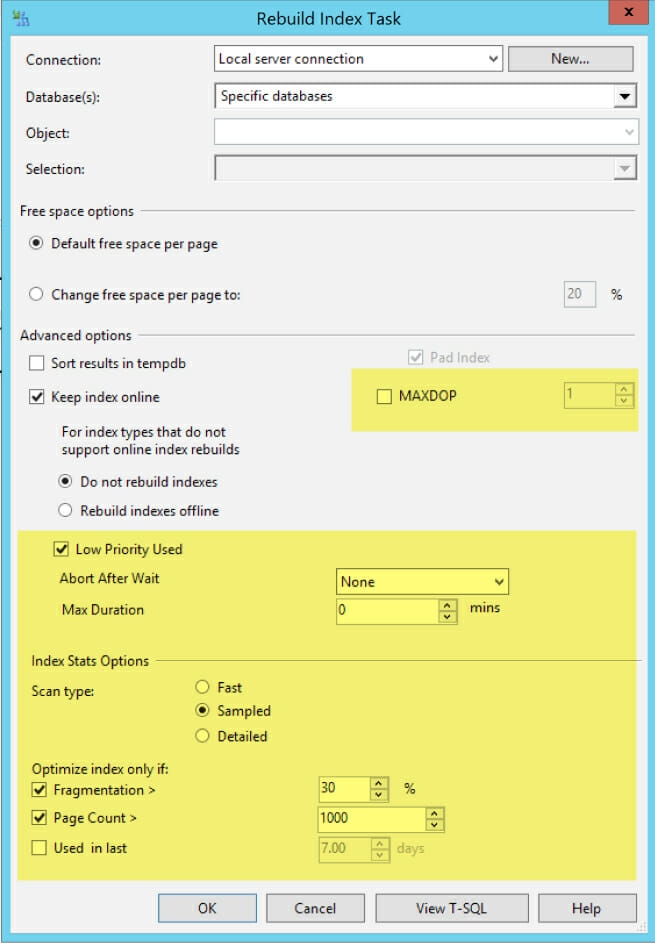
Things that are better for Index Rebuild for Enterprise Edition: Maxdop, Low Priority
You can now configure MAXDOP for index rebuilds in a maintenance plan. This feature has existed since SQL Server 2005, but you had to use TSQL to specify it before. Using more than one core for index rebuild operations is an Enterprise feature. This will work in Enterprise Edition and Developer Edition, but you’re only going to get single threaded rebuilds in Standard Edition.
You can also configure online index rebuilds to wait at low priority. This feature was added in SQL Server 2014, and it’s specific to the Enterprise Online Rebuild option. It can reduce blocking chains for the locks needed for the index maintenance, and it now gives you options about what you’d like to happen after waiting (just like the TSQL).
Things that are better for all editions: Fragmentation Level and Page Count
The ability to skip indexes that are tiny, or which aren’t very fragmented is a big improvement, and brings this task into the modern world. Partly. (More on that below.)
Things that confused me: Index Stats Options - Scan type
I had a serious case of Wishful Thinking (TM) when it came to the bottom part of this dialog box.
The problem was the phrase ‘index stats options’. I was SURE that the word ‘stats’ here was related to the statistics in SQL Server that describe the data distribution in columns or indexes, that are used by the optimizer when generating execution plans. I thought that a feature had been added to this task where it might update index or column statistics if the index wasn’t fragmented enough to qualify for a rebuild (something that the more sophisticated free scripts above do). I was thinking that ‘Sampled’ was a dynamic sample, and ‘Detailed’ was perhaps FULLSCAN.
Nope. Nope. Nope. After much confusion, I realized that in fact this has nothing to do with those stats.
Instead, this part of the dialog lets you control how the task checks the level of fragmentation in the index from the sys.dm_db_index_physical_stats DMV: Fast = ‘LIMITED’, Sampled = ‘SAMPLED’, ‘Detailed’=‘DETAILED’. (I did some tracing to confirm the mapping.)
It is kinda nice that 2016 now lets you configure this, although generally you just want to use ‘LIMITED’, aka ‘Fast’. This is the default, and it’s what most free scripts out there do.
The Reorganize Index Task got a little makeover in 2016, too
Here is the task, with the new options highlighted:
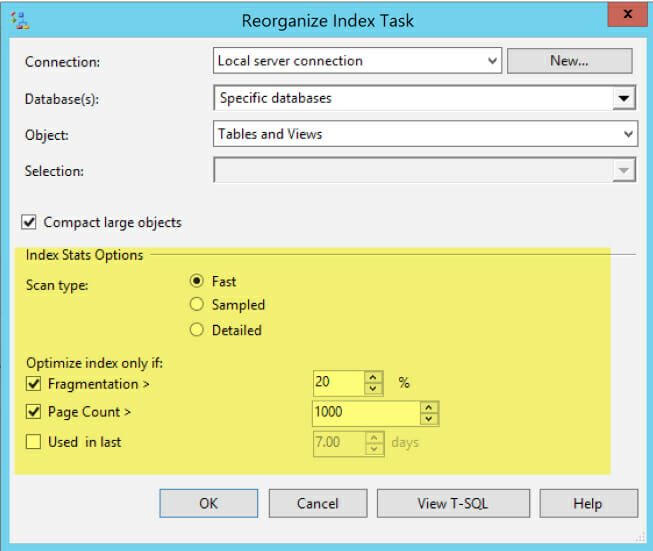
Reorganize is always single threaded and online, in every edition, so we don’t have options for that. But we can now skip small indexes, skip indexes that aren’t very fragmented, and control the level of thoroughness of the scan in sys.dm_db_index_physical_stats.
What problems do maintenance plans still have for index and statistics maintenance in 2016?
Maintenance plans still have a few problems when it comes to index and stats maintenance, and the more data you have, the more they’ll hurt.
1) You’ll probably end up sampling the same objects for fragmentation more than once
Let’s say that I configure my maintenance plan like this:

Disclaimer: This is a totally simplified maintenance plan and it doesn’t clean up any of its mess at all. I’m showing this to talk about the problems it has and to try to help you justify using a different solution, not to show you best practices with it :)[/caption]
I configure it conservatively, to save effort:
- The rebuild task only rebuilds indexes over 50% fragmented which can be rebuilt online
- The reorganize task only reorganizes indexes over 25% fragmented
What if the rebuild index task finds a 20GB index that’s 60% fragmented and rebuilds it?
Well, when reorganize comes along, it will see that the 20GB index isn’t fragmented – but it still has to take the time to sample it all over again to see that, because these are separate tasks. (I did some tracing to confirm that each task scans the fragmentation individually, and they do.)
In contrast, a clever script will step through the indexes, skip low page counts based on metadata, sample fragmentation once, and then decide whether to rebuild or reorganize.
2) These tasks don’t do anything new for index and column statistics (the other kind of stats)
When it comes to performance, maintaining index and column statistics often makes more of a difference than defragmenting your indexes.
Sure, you need to address index fragmentation sometimes. If you never defragment your indexes, you’ll end up with tons of trapped empty space and bloated indexes - and that wastes space not only on disk, but also in memory.
But for many databases, updating index and column statistics – the little objects that help SQL Server estimate how much data there is – can make a major difference to performance, and it’s helpful to update them on a regular basis.
Generally, you want to integrate statistics maintenance with index maintenance, if you’re running both, because rebuilding an index automatically gives it nice fresh statistics (equivalent to updating them with fullscan).
But maintenance plans don’t have a feature to be smart about these stats.
3) The Update Statistics task is waaaaay nastier than it looks at first
One of my least favorite things about maintenance plans is this task, because SQL Server is so much smarter than this! This task is really outdated and very problematic, but you’d never know until it burns you. Here it is with the default values selected:
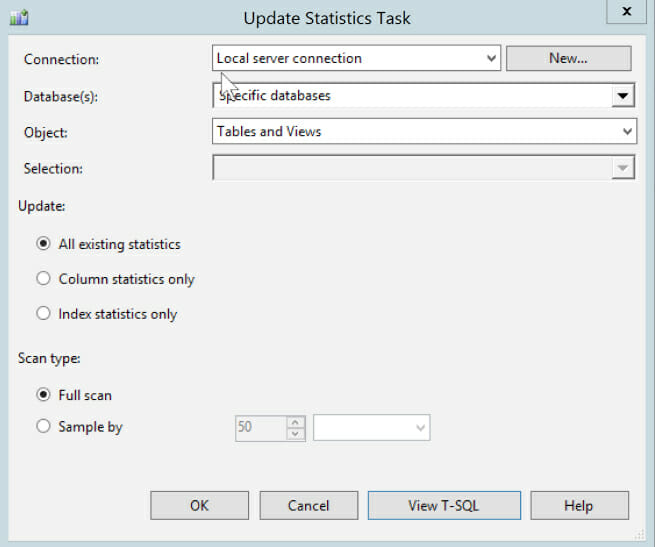
Problems with this task:
- It bulldozes through all your statistics, whether or not they have had any modifications since they were last updated. If you have the “auto-create statistics” setting enabled (it’s on by default, and it’s a very good thing), you may have tons and tons of little column statistics. The statistics are a good thing: blindly updating them all isn’t.
- It defaults to FULLSCAN. Updating statistics on a table with FULLSCAN will repeatedly scan the table and/or indexes on the table, and can take a very long time.
- The only other option is a hardcoded sample. It defaults to 50 rows, but you could change it to a percentage. This is a lousy choice.
More clever maintenance scripts:
- Skip statistics maintenance on an index that has been rebuilt (because it got a stats update with that operation)
- Checks other index-related statistics and column statistics to see if they’ve been modified, and skips them if they haven’t had any action
- Allows you to use the default dynamic sampling for statistics update. This dynamic sampling is built into the UPDATE STATISTICS command (the maintenance plan just doesn’t give an option for it). For small objects, it’ll decide to scan the whole thing. For larger objects it will take a sampling of rows.
3b) This means that the imperfect workaround of sp_updatestats lives on
Many folks get wise to the fact that the Update Statistics task isn’t their friend after they realize that it’s making their maintenance take forever. Often what they turn to instead is an ‘Execute TSQL Statement’ task. They use it to execute some code calling the built-in procedure sp_updatestats for each database they care about.
While sp_updatestats is definitely a bit smarter (it skips stats with not changes, and it uses the dynamic sampling), it has some flaws itself. Erin Stellato summarizes the problems with sp_updatestats in this post.
4) You don’t get configuration options for partitioned indexes
Feature recap:
- In SQL Server 2016 SP1, we got the ability to use table partitioning in Standard, Web, and Express Edition
- In SQL Server 2014, we got the ability to rebuild individual partitions online in Enterprise Edition. In Standard Edition, rebuild is offline, but you have the choice between doing individual partitions and the whole index.
But I don’t see any options about partitioning in those Index Rebuild and Reorganize dialogue boxes, do you?
So I did some basic testing. I pointed my maintenance plan at a partitioned table, and asked it to script out the TSQL it would use (this is an estimate, not a guarantee). Here’s an excerpt of what it gave me:
USE [BabbyNames]
GO
ALTER INDEX [cx_pt_FirstNameByBirthDate_1966_2015] ON [pt].[FirstNameByBirthDate_1966_2015] REBUILD PARTITION = 5 WITH (SORT_IN_TEMPDB = OFF, ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 0 MINUTES, ABORT_AFTER_WAIT = NONE)), DATA_COMPRESSION = ROW)
GO
USE [BabbyNames]
GO
ALTER INDEX [cx_pt_FirstNameByBirthDate_1966_2015] ON [pt].[FirstNameByBirthDate_1966_2015] REBUILD PARTITION = 6 WITH (SORT_IN_TEMPDB = OFF, ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 0 MINUTES, ABORT_AFTER_WAIT = NONE)), DATA_COMPRESSION = ROW)
GO
USE [BabbyNames]
GO
ALTER INDEX [cx_pt_FirstNameByBirthDate_1966_2015] ON [pt].[FirstNameByBirthDate_1966_2015] REBUILD PARTITION = 13 WITH (SORT_IN_TEMPDB = OFF, ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 0 MINUTES, ABORT_AFTER_WAIT = NONE)), DATA_COMPRESSION = ROW)
GO
So it appears that at least on SQL Server 2016 SP1, it defaults to partition level rebuilds, whether you ask for them or not. It also appears to check the fragmentation level for each partition, and skip those beneath the specified fragmentation level.
If you want to skip any partitions all the time or rebuild some indexes entirely and not at the partition level, there’s no option for that.
5) There’s no good options for exclusion
I may have some large objects in my database that I don’t want to regularly maintain. One common example are logging tables, where data may be frequently inserted, but they are queried only rarely, if internal staff need to investigate a problem. You may have some indexes on the tables to help with these queries, but you don’t care much about their performance.
If you don’t have a lot of time for maintenance, you probably want to skip these tables most of the time, and only do the barest of maintenance once a month, or possibly even less frequently. This can let you focus on the objects you care about in limited time.
Maintenance plans don’t have a good way to do this. You can select specific objects, but not exclude specific objects, and you have to configure it on every task. This can lead to inconsistencies, or to new objects not being picked up by the maintenance plans.
What to do?
If you read all the way through this looooong post, I’m guessing that you’re not completely happy with your maintenance plan. You’d like to improve it.
Good news! There are lots of great ways you can do that. The SQL Server community has lots of clever folks who built them and want to share them with you.
Your best option is to look at the websites for Ola Hallengren’s free scripts and Minion Reindex. Check out the documentation a little. Decide which you’d like to test out, and grab the code and put it on a test server. Make a change plan to replace your maintenance plans with one of those instead.
What if you have a mandate from your management to use the built-in maintenance plans?
This would be my question: is it OK for us to run custom code in maintenance plans? Like for that situation where the built-in Update Statistics command doesn’t work, is it OK for me to run a script that’s smarter about statistics maintenance?
If there’s any leeway at all for that, then you’ve got a little bit of an open door to work with. You can start the process of getting external free scripts and their licenses reviewed.
If there isn’t any leeway at all for that, then I would make the best of what I have, and keep an eye out for places where we have problems due to the limitations in maintenance plans. If you come across incidents where using an improved script might work, then you have a good opportunity to bring it up again in a friendly way.