on June 14, 2017
When I was recently working on the course, “Should Developers Manage Index Maintenance?” I explained that in my experience, statistics maintenance can make more of a difference to performance than index maintenance can.
I also noted that one of the big “maintenance goofs” that I’ve made in the past is to be overly eager to update statistics. And to update them with FULLSCAN.
Here’s some detail on why doing that can be so slow, and how it can eat up more resources than you might think. (This is a long one, so scroll on down to the end of the post for a list of spoilers, if you like.)
When you update statistics against a table, SQL Server may have to scan the table many, many times
When people manually update statistics, they generally don’t update just a single column stats, or stats for a single index. They identify a table that’s a problem, and create a command to update stats against the whole table.
The command to update statistics against an entire table looks something like this:
UPDATE STATISTICS dbo.FirstNameByBirthDate_1966_2015;
GO
But then, if they’ve gone to this trouble, they think, “I should try to make the updated statistics as accurate as possible!”
The obvious way to do that it to tell SQL Server to do more than just take a sample of the data: instead to do it with FULLSCAN.
So they use a command like this:
UPDATE STATISTICS dbo.FirstNameByBirthDate_1966_2015 WITH FULLSCAN;
GO
How much longer does FULLSCAN take?
On my test instance, the command that uses the default sampling takes 6 seconds to complete.
The command which adds “WITH FULLSCAN” takes just over five minutes to complete.
The reason is that those two little words can add a whole lot of extra IO to the work of updating statistics.
What is update statistics really doing?
My table is pretty narrow. It has only six statistics on it: I queried information about them with a query like this.
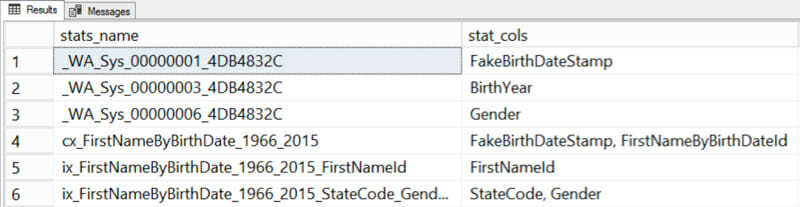
The three statistics with the funny names beginning in _WA_Sys are column statistics that SQL Server automatically created when I ran queries with joins or where clauses using those columns. The other three statistics were automatically created when I created indexes.
I ran a trace when I updated statistics with FULLSCAN, and here’s what I saw, stat by stat…
1) FakeBirthDateStamp and FirstNameByBirthDateId (cx_FirstNameByBirthDate_1966_2015)
The clustered index has a two-column statistic. Those two columns match up with this query in the trace:
SELECT StatMan([SC0], [SC1]) FROM
(SELECT TOP 100 PERCENT [FirstNameByBirthDateId] AS [SC0], [FakeBirthDateStamp] AS [SC1] FROM [dbo].[FirstNameByBirthDate_1966_2015] WITH (READUNCOMMITTED) ORDER BY [SC0], [SC1] )
AS _MS_UPDSTATS_TBL OPTION (MAXDOP 4);
GO
Here’s the plan I saw in the trace:
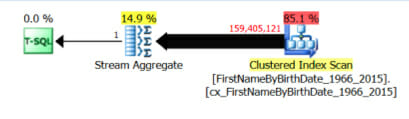
There are only two columns output from the clustered index scan: FirstNameByBirthDateId and FakeBirthDateStamp, the two columns needed to update the stat.
(Note: this plan does seem a bit odd to me, as it could have found these columns in a non-clustered index: these are the key columns in the clustered index, which will be present in each nonclustered index, whether we ask for it or not. But it chose to use the clustered index.)
2) FakeBirthDateStamp column stat (_WA_Sys_00000001_4DB4832C)
Next, SQL Server went to work on the FakeBirthDateStamp column statistic.
“But wait!” you might think. “We just got that info when updating the stat for the clustered index!”
Yes, we did. But we’re going to go scan something else, anyway, because that’s how we roll. We need to independently collect data for each statistic, even though you ran the command against the whole table.
Here’s the query that SQL Server runs next, which lines up with the column stat:
SELECT StatMan([SC0])
FROM (SELECT TOP 100 PERCENT [FakeBirthDateStamp] AS [SC0]
FROM [dbo].[FirstNameByBirthDate_1966_2015] WITH (READUNCOMMITTED) ORDER BY [SC0] )
AS _MS_UPDSTATS_TBL OPTION (MAXDOP 4);
GO
Here is the plan it used to get the data to update the column statistic:

This time, SQL Server chose to scan the nonclustered index on FirstNameId. Looking at the properties of the scan, it figured out that FakeBirthDateStamp would be there (because of the clustering key), and decided to scan this nonclustered index and output just that column:
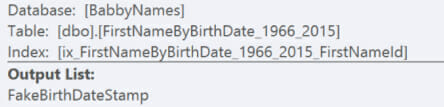
But … oops! We didn’t allocate enough memory for our sort and had a little spill in tempdb.
3) BirthYear (_WA_Sys_00000003_4DB4832C)
If you’re still reading, here’s where things get crazier than I expected.
BirthYear is a computed column. SQL Server uses the following query to gather data to update my column statistic…
SELECT StatMan([SC0])
FROM (SELECT TOP 100 PERCENT [BirthYear] AS [SC0]
FROM [dbo].[FirstNameByBirthDate_1966_2015] WITH (READUNCOMMITTED)
ORDER BY [SC0] ) AS _MS_UPDSTATS_TBL OPTION (MAXDOP 4);
GO
And here’s the plan I got:

Here’s the play by play of what that plan is doing:
- Scan the nonclustered index on FirstNameId, and output the “secret” FakeBirthDateStamp column (which is there because it’s part of the clustered index)
- Use compute scalar operators to apply the formula for the BirthYear column and compute it for every row
- Then we have our tempdb spill again
Computed columns can have statistics on them. That’s a good thing. I don’t have a non-clustered index on this column for SQL Server to scan, but I was surprised that it wanted to re-compute every single row for it, because I did mark this column as ‘persisted’ (I double-checked with a query).
But this time, SQL Server really didn’t want to scan that clustered index again (we just did it, after all), so it decided to recompute every. Single. Row.
We’re not done yet, though. We’re only halfway through the statistic!
4) FirstNameId (ix_FirstNameByBirthDate_1966_2015_FirstNameId)
We’ve scanned every row in the nonclustered index on FirstNameId twice already. But we haven’t actually updated its statistic yet, so… you guessed it, let’s scan it again!
The query to gather data to update this stat is…
SELECT StatMan([SC0], [SC1], [SC2])
FROM (SELECT TOP 100 PERCENT [FirstNameId] AS [SC0], [FirstNameByBirthDateId] AS [SC1], [FakeBirthDateStamp] AS [SC2]
FROM [dbo].[FirstNameByBirthDate_1966_2015] WITH (READUNCOMMITTED)
ORDER BY [SC0], [SC1], [SC2] ) AS _MS_UPDSTATS_TBL OPTION (MAXDOP 4);
GO
And the plan was…

Look on the bright side: it may be the third time we’ve scanned this nonclustered index, but at least this time we didn’t have any tempdb spills.
5) StateCode, Gender (ix_FirstNameByBirthDate_1966_2015_StateCode_Gender_INCLUDES)
We’ve got another nonclustered index, and it has two key columns. Those two columns are in the auto-generated index statistic. To gather information for them, SQL Server runs this query:
SELECT StatMan([SC0], [SC1], [SC2], [SC3])
FROM (SELECT TOP 100 PERCENT [StateCode] AS [SC0], [Gender] AS [SC1], [FirstNameByBirthDateId] AS [SC2], [FakeBirthDateStamp] AS [SC3]
FROM [dbo].[FirstNameByBirthDate_1966_2015] WITH (READUNCOMMITTED) ORDER BY [SC0], [SC1], [SC2], [SC3] )
AS _MS_UPDSTATS_TBL OPTION (MAXDOP 4);
GO
This gets a plan that scans the associated nonclustered index:

6) Gender (_WA_Sys_00000006_4DB4832C)
Whew, I’m glad this is a narrow table. We have a column statistic on Gender. This might look like a duplicate stat to the index statistic — but note that the index statistic leads on StateCode. That turns out to make it quite different (because only the leading column in a statistic gets information in the histogram). So the column statistic on Gender only is really quite different.
Again, SQL Server can’t re-use any of the information it previously scanned. It runs this query:
SELECT StatMan([SC0])
FROM (SELECT TOP 100 PERCENT [Gender] AS [SC0]
FROM [dbo].[FirstNameByBirthDate_1966_2015] WITH (READUNCOMMITTED) ORDER BY [SC0] )
AS _MS_UPDSTATS_TBL OPTION (MAXDOP 4);
GO
Which gets this execution plan:

Confession: this execution plan makes me a little sad. I knew I wasn’t going to get a happy ending for this post, but I was really rooting for it to at least scan the nonclustered index on StateCode and Gender (which is physically much smaller).
Nope. It decided to scan the whole clustered index, again, this time to output the Gender column. And it spilled 97K pages in tempdb.
What I used to see this info
I set up a quick and sloppy extended events trace to get the following events:
- query_post_execution_showplan - this impacts performance when you collect it, so I also updated statistics without the trace running to measure basic timing
- sp_statement_completed - this shows you information for each “SELECT StatMan” statement run behind the scenes
- sql_statement_completed - this gives you overall information for the whole ‘UPDATE STATISTICS dbo.FirstNameByBirthDate_1966_2015 WITH FULLSCAN;’ when it finishes
The query execution plan screenshots are from the free SentryOne Plan Explorer, taken with Snagit.
Summing up and takeaways
Here’s what you need to know:
- If you must manually update statistics, stick with the default sampling (unless you have a great reason to do otherwise)
- If you must manually update statistics, update a specific column or index stat only (unless you have a great reason to do otherwise)
- If you can come up with a better way to get stabile high performance, such as tuning queries or indexes, it removes this headache
This is because:
- For every statistic you update (even as part of a command to update statistics on a whole table), SQL Server has to do a separate read operation
- When you use FULLSCAN, this means scanning a table or an index
- SQL Server may choose to recompute all the values in a computed column, even if it’s persisted, when you update that column statistic with FULLSCAN
- SQL Server may not always choose to scan a nonclustered index instead of the clustered index, even when that seems like a viable option
- Updating statistics can generate activity you might not expect, like spills in tempdb, if it underestimates how many resources it will need for things like SORT operators in the plan
Who knew that so much weirdness could come from such a simple command?!?!?