on May 24, 2017
Nonclustered indexes are awesome in SQL Server: they can get you huge performance gains.
But we can’t always create the perfect index for every query. And sometimes when SQL Server finds an index that isn’t quite perfect and decides to use it, it might make your query slower instead of faster.

Here’s an example of why that can happen, and some reasons why if you hit something like this, the FORCESCAN table hint may help (and also why you should be careful with that).
The setup
I’ve restored the large BabbyNames sample database and created a couple of indexes:
USE BabbyNames;
GO
CREATE INDEX ix_ref_FirstName_INCLUDES on ref.FirstName (FirstName) INCLUDE (FirstNameId);
GO
CREATE INDEX ix_dbo_FirstNameByBirthDate_1966_2015_FirstNameId on dbo.FirstNameByBirthDate_1966_2015 (FirstNameId)
GO
Meet my slow query
My query has a simple join, and a GROUP BY clause. We’re looking for the count of all the babies born named “Matthew”, grouped by Gender:
SELECT Gender, COUNT(*)
FROM dbo.FirstNameByBirthDate_1966_2015 AS fnbd
JOIN ref.FirstName as fn on
fnbd.FirstNameId=fn.FirstNameId
where fn.FirstName='Matthew'
GROUP BY Gender;
GO
SQL Server thinks this query is going to be cheap
The query has cost of 19.75. SQL Server estimates that it’s going to get 6,016 rows back from dbo.FirstNameByBirthDate_1966_2015 for all those Matthews.
Since that’s not a lot of rows, it decides to use the narrow nonclustered index on FirstNameId to find the Matthews, and then go do a key lookup to pick up the Gender column in the clustered index of the table. Here is what the estimated execution plan looks like:
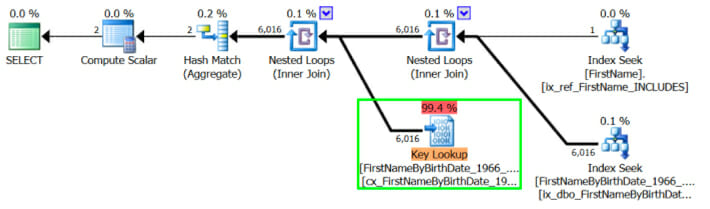
But SQL Server is underestimating the number of Matthews by a lot
This table has a row for every baby named Matthew in the United States between 1966 and 2015. There are a lot more Matthews than 6K. Our estimate is off by around 1.4 million.
When SQL Server chooses this plan, the query takes around 13 seconds to execute. Running all those nested loops with a single thread isn’t quick!
Spoiler: if this nonclustered index didn’t exist (or wasn’t selected), the query would execute in around 5 seconds (instead of 13 seconds), just scanning the clustered table_._
Why is the estimate so low?
I’m using the new cardinality estimator in SQL Server, so I used a few trace flags (more on those from Paul White here) to get SQL Server to write out some information about which statistics it used to my ‘Messages’ tab when I compiled the query:
SELECT Gender, COUNT(*)
FROM dbo.FirstNameByBirthDate_1966_2015 AS fnbd
JOIN ref.FirstName as fn on
fnbd.FirstNameId=fn.FirstNameId
where fn.FirstName='Matthew'
GROUP BY Gender
OPTION
( RECOMPILE,
QUERYTRACEON 3604,
QUERYTRACEON 2363
);
GO
Among lots of other details, it told me “Loaded histogram for column QCOL: [fnbd].FirstNameId from stats with id 4”
I used dynamic management views to confirm that my statistic with id 4 on FirstNameByBirthDate_1966_2015 is the stat for the index ix_dbo_FirstNameByBirthDate_1966_2015_FirstNameId.
So let’s look at that stat!
DBCC SHOW_STATISTICS (FirstNameByBirthDate_1966_2015, ix_dbo_FirstNameByBirthDate_1966_2015_FirstNameId);
GO
Here’s the statistic, with a few minor embellishments…
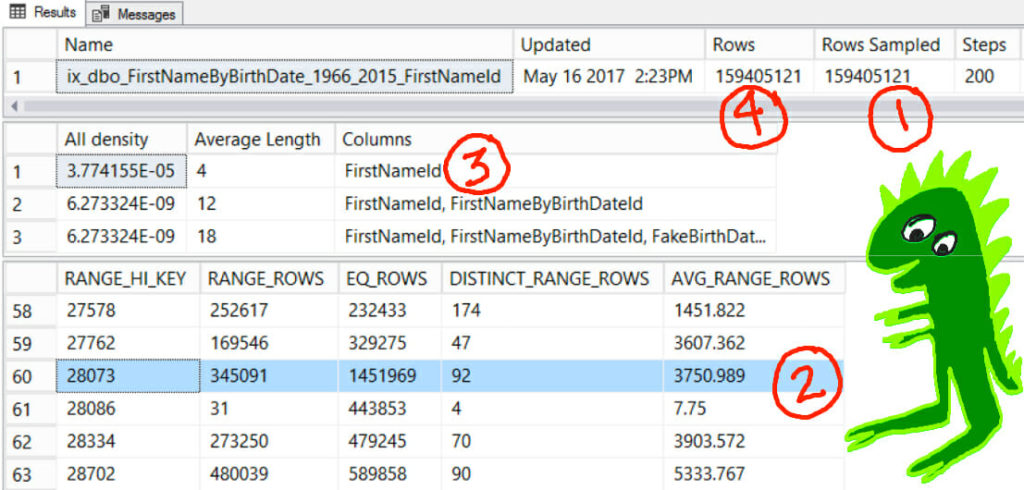
Things to notice, by number:
- “Rows Sampled” in the header is equal to all the rows in the table. This statistic was created when the index was created, and so it automatically got “fullscan”. SQL Server sampled all of the rows when it created this stat.
- The blue highlighted row is in the section called the Histogram of the statistic. The FirstNameId for ‘Matthew’ is 28,073. This value happened to get its own row in the histogram, and SQL Server knows that there are approximately 1,451,969 rows in this table of Matthews. That’s way more than the estimate of 6,016! The histogram didn’t get used.
- The “All density” number for just the FirstNameID column is 3.774155E-05 – aka 0.00003774155. This number is in what’s called the “density vector” for the index, and it’s used for when SQL Server is going to guess how many rows come back for an “average” FirstNameId (not a specific FirstNameId). And looking at our query, we didn’t give it a specific FirstNameId. We put the predicate over on ref.FirstName, using the FirstName column.
- Rows = 159,405,121. This is the other ingredient to our formula to “guess how many rows exist for an average FirstNameId.”
- All density * rows = 0.00003774155 * 159,405,121 = 6,016.19634447755
To be clear, the problem here is not the new cardinality estimator. The legacy cardinality estimator also chooses a nested loop plan and is just as slow for this query.
The slow performance is because of the way we wrote our query
We wrote our query putting a predicate on FirstName on the dimension table, ref.FirstName, then joined over to dbo.FirstNameByBirthDate_1966_2015. SQL Server has to generate the execution plan for the query before it runs. It can’t query ref.FirstName and find out what the FirstNameId is for Matthew, then use that to figure out what kind of join to use.
(At least not yet. Plans like this can potentially be fixed by the Adaptive Join feature in future releases, but it doesn’t cover this in the initial SQL Server 2017 release. They can’t tackle everything at once.)
Instead, SQL Server has to say, “Well, for any given name that I join on, what looks like the best bet?”
And that’s why it uses the density vector on the statistic multiplied by the rowcount. There’s nothing wrong with the statistic.
What if we wrote our query differently and specified the FirstNameId for Matthew?
SELECT Gender, COUNT(*)
FROM dbo.FirstNameByBirthDate_1966_2015 AS fnbd
JOIN ref.FirstName as fn on
fnbd.FirstNameId=fn.FirstNameId
where fn.FirstNameId = 28073
GROUP BY Gender;
In this case, SQL Server looks at the histogram for the FirstNameId and gives us a very different estimated plan:
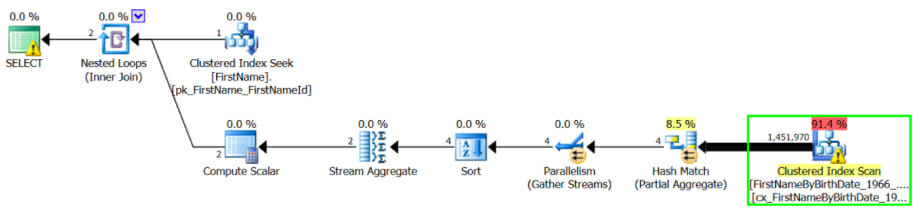
But it can only do this because we gave it the FirstNameId.
Knowing about all those Matthews at the time of compilation, SQL Server decides it may as well just go ahead and scan the clustered index using parallelism. It also asks for a nonclustered index on Key (FirstNameId) INCLUDE (Gender).
This query takes around 5 seconds (instead of 13 seconds). Scanning that clustered index isn’t awesome, but it’s more than twice as fast as using the imperfect nonclustered index on FirstNameId and then going back to look up Gender.
Is there another way to fix this?
This is a pretty simple example. You can’t always just change the query to specify just the right predicate like FirstNameId = 28073.
Sometimes, the FORCESCAN table hint can help. Here’s what the documentation explains (in brief, click to read more detail including limitations):
Introduced in SQL Server 2008 R2 SP1, this hint specifies that the query optimizer use only an index scan operation as the access path to the referenced table or view. The FORCESCAN hint can be useful for queries in which the optimizer underestimates the number of affected rows and chooses a seek operation rather than a scan operation.
If we know that every time we want this query to run, we do not want it to do a seek on an index, we could add this hint. We don’t even have to specify an index with it, we can do this:
SELECT Gender, COUNT(*)
FROM dbo.FirstNameByBirthDate_1966_2015 AS fnbd with (FORCESCAN)
JOIN ref.FirstName as fn on
fnbd.FirstNameId=fn.FirstNameId
where fn.FirstName='Matthew'
GROUP BY Gender;
GO
We get a slightly different estimated plan…

But again the query completes in around 5 seconds instead of 13. And again it registers a request for an index on Key (FirstNameId) INCLUDE (Gender).
What if we use FORCESCAN and then someone adds the perfect index?
Let’s say that we found this slow query, and for whatever reason it didn’t make sense to give it the “perfect” index. So we added a FORCESCAN hint to make it faster.
But later on, we found other queries who would use the same index that this query wanted. And eventually we ditched the index on just FirstNameId and replaced it with:
CREATE INDEX ix_dbo_FirstNameByBirthDate_1966_2015_FirstNameId_Includes on dbo.FirstNameByBirthDate_1966_2015 (FirstNameId) INCLUDE (Gender)
GO
This index is great for this query! It makes our original query (with no hints) complete in less than half a second, using a simple index seek!
But if we have that FORCESCAN hint in place, SQL Server can use the new, perfect index but…. yeah, it’s forced to scan it. The hint name isn’t kidding.
Forcing the scan of the perfect index takes around six seconds.
Takeaways
When you add a non-clustered index, it’s possible for this to cause performance regressions in some of your queries.
When you see a low estimate in a query in SQL Server, the problem isn’t always that the statistics are “bad”. SQL Server may have very accurate data in the statistics, but may not be able to use it perfectly because of the way the query is written.
The FORCESCAN table hint can be used to change the behavior of a query without specifying an index by name – but if you use this hint, you need to periodically check and make sure that the hint is still making the query faster, not slower.
Want to learn about more query hints?
Check out my free course, Query Tuning with Hints & Optimizer Hotfixes!