on March 21, 2017
I’ve never claimed to be great at math, but until recently I thought I knew how to count to one. Zero… one. That’s what we learned in kindergarten.
Apparently SQL Server didn’t go to kindergarten.

Because it can’t even count to one in some execution plans.
I have a very simple query. It’s running against a table with a nonclustered columnstore index.
SELECT COUNT(*) FROM pt.FirstNameByBirthDate_1966_2015;
GO
The query returns one row, as expected. Here’s my count:
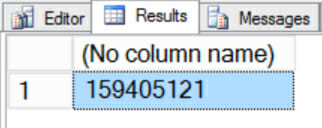
For the record, that is the correct number of rows in the table. Here’s where things get weird. In the actual execution plan, the columnstore index returns zero rows.
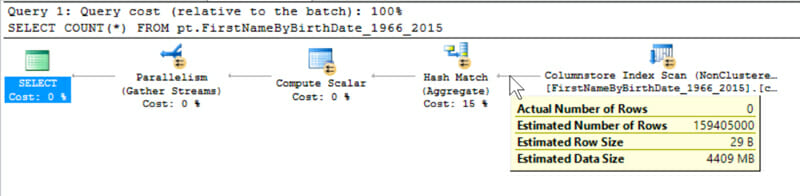
Yes, this is really the actual execution plan. I’m not tricking you, I promise.
Zero rows go into the hash match, but one row comes out
It would appear that this hash match has conjured a row from nowhere. If we look to the left of the hash match, a row appears!
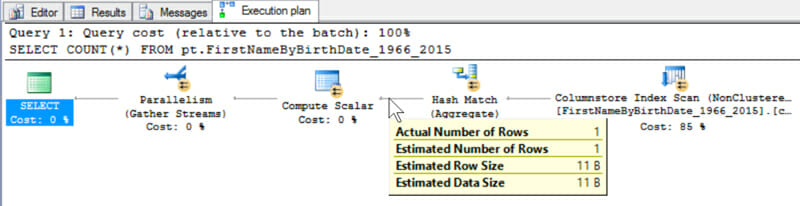
Our hash match operator is psychic. Did it phone a hotline to find out the count of this table? If so, why is the columnstore index scan in the plan in the first place?
Let’s look at the properties of the columnstore scan
Things get even weirder.
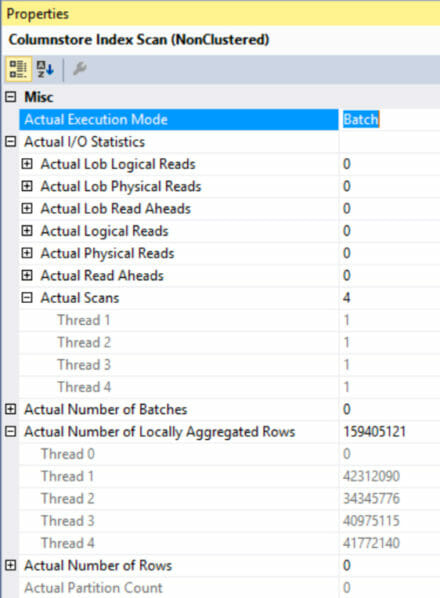
The columnstore index scan executed in batch mode and used 4 cores. It did a scan with each thread, although somehow it did ZERO reads and accessed ZERO partitions in my partitioned table. (Whaaatttt?)
But it did do work. It did fancy, expensive work. Look at those locally aggregated rows!
This is an Enterprise Edition optimization for batch mode columnstore
These locally aggregated rows are called ‘aggregate pushdown’. Aggregate pushdown is one of the enhancements that remains an Enterprise Only feature, even after SQL Server 2016 SP1. (Sunil Agarwal discusses these features here.) It makes your columnstore indexes even faster.
But that just looks wrong! It still outputs a row!
I agree, it looks wrong. So I asked Niko about it, because if anyone thinks like a columnstore index, it’s Niko. I asked when I was at SQLSaturday Portugal, too, which was just an awesome event, so I could ask in person and see his face.
I asked, “Is this a bug in my execution plan? Or a feature?”
Niko explained that it’s a feature. Or at least, it’s on purpose. It’s just not very good at drawing lines. What the execution plan is trying to say is more like this:

The plan is trying to explain that the hash match doesn’t have to do any of the counting, because the columnstore index did it all with enterprise magic.
But… but… that doesn’t look right
SQL Server is drunk. At least, that’s what I said to Niko. And his face said that he perhaps agrees with me. It’s not like Niko drew the lines, so don’t blame him! But he did confirm that this is not a bug in execution plans, this was done on purpose.
I guess if it’s using “new math”, SQL Server can count those rows however it wants.