on June 7, 2016
I received a question from a reader who was testing out a partitioning architecture:
We are testing table partitioning using one filegroup per partition. When we merge a boundary point, we see that partition_number changes in sys.partitions. Does this mean that data movement is occurring?
Short Answer: Just because partition_number is changing does NOT mean there is “data movement”.
Better Answer: You can tell for sure whether data movement is happening in a test environment by having a script that shows how much data is in each filegroup before and after you merge! This is worth doing so you know exactly what’s going on with your setup.
Let’s take a look at the ‘Better Answer’ here.
Our Test Partition Setup: the mergethis database
This script creates a testing database named merge this with an extra 10 filegroups. I’ve been irresponsible and put them on the C drive, but I bet you’re smarter than that and would never risk filling up your system drive.
SET NOCOUNT ON;
GO
use master;
GO
IF DB_ID('mergethis') IS NOT NULL
BEGIN
ALTER DATABASE mergethis SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE mergethis;
END
GO
CREATE DATABASE mergethis
GO
ALTER DATABASE mergethis
ADD FILEGROUP fg_mergethis_1;
GO
ALTER DATABASE mergethis
ADD FILEGROUP fg_mergethis_2;
GO
ALTER DATABASE mergethis
ADD FILEGROUP fg_mergethis_3;
GO
ALTER DATABASE mergethis
ADD FILEGROUP fg_mergethis_4;
GO
ALTER DATABASE mergethis
ADD FILEGROUP fg_mergethis_5;
GO
ALTER DATABASE mergethis
ADD FILEGROUP fg_mergethis_6;
GO
ALTER DATABASE mergethis
ADD FILEGROUP fg_mergethis_7;
GO
ALTER DATABASE mergethis
ADD FILEGROUP fg_mergethis_8;
GO
ALTER DATABASE mergethis
ADD FILEGROUP fg_mergethis_9;
GO
ALTER DATABASE mergethis
ADD FILEGROUP fg_mergethis_10;
GO
ALTER DATABASE mergethis ADD FILE ( NAME = file_mergethis_1, FILENAME = 'C:\MSSQL\DATA\fg_mergethis_1.ndf') TO FILEGROUP fg_mergethis_1;
GO
ALTER DATABASE mergethis ADD FILE ( NAME = file_mergethis_2, FILENAME = 'C:\MSSQL\DATA\fg_mergethis_2.ndf') TO FILEGROUP fg_mergethis_2;
GO
ALTER DATABASE mergethis ADD FILE ( NAME = file_mergethis_3, FILENAME = 'C:\MSSQL\DATA\fg_mergethis_3.ndf') TO FILEGROUP fg_mergethis_3;
GO
ALTER DATABASE mergethis ADD FILE ( NAME = file_mergethis_4, FILENAME = 'C:\MSSQL\DATA\fg_mergethis_4.ndf') TO FILEGROUP fg_mergethis_4;
GO
ALTER DATABASE mergethis ADD FILE ( NAME = file_mergethis_5, FILENAME = 'C:\MSSQL\DATA\fg_mergethis_5.ndf') TO FILEGROUP fg_mergethis_5;
GO
ALTER DATABASE mergethis ADD FILE ( NAME = file_mergethis_6, FILENAME = 'C:\MSSQL\DATA\fg_mergethis_6.ndf') TO FILEGROUP fg_mergethis_6;
GO
ALTER DATABASE mergethis ADD FILE ( NAME = file_mergethis_7, FILENAME = 'C:\MSSQL\DATA\fg_mergethis_7.ndf') TO FILEGROUP fg_mergethis_7;
GO
ALTER DATABASE mergethis ADD FILE ( NAME = file_mergethis_8, FILENAME = 'C:\MSSQL\DATA\fg_mergethis_8.ndf') TO FILEGROUP fg_mergethis_8;
GO
ALTER DATABASE mergethis ADD FILE ( NAME = file_mergethis_9, FILENAME = 'C:\MSSQL\DATA\fg_mergethis_9.ndf') TO FILEGROUP fg_mergethis_9;
GO
ALTER DATABASE mergethis ADD FILE ( NAME = file_mergethis_10, FILENAME = 'C:\MSSQL\DATA\fg_mergethis_10.ndf') TO FILEGROUP fg_mergethis_10;
GO
Now Create a Partition Function, Partition Scheme, and a Table
Now we create a partition function named pf_merge_this, which specifies that we’re partitioning by a column with the date type. We have nine boundary points– we’re partitioning by every one day. We’re using RANGE LEFT in this example.
Our script then creates a partition scheme that maps each partition to a single filegroup. This is also a choice. The more filegroups you decide to use, the more complex your code becomes if you’re splitting and merging boundary points.
use mergethis;
GO
CREATE PARTITION FUNCTION pf_mergethis (date)
AS RANGE LEFT
FOR VALUES (
'2016-01-01', '2016-02-01', '2016-03-01', '2016-04-01', '2016-05-01', '2016-06-01', '2016-07-01', '2016-08-01', '2016-09-01');
GO
CREATE PARTITION SCHEME ps_mergethis
AS PARTITION pf_mergethis
TO ([fg_mergethis_1],[fg_mergethis_2],[fg_mergethis_3],[fg_mergethis_4],[fg_mergethis_5],[fg_mergethis_6],[fg_mergethis_7],[fg_mergethis_8],[fg_mergethis_9],[fg_mergethis_10]);
GO
CREATE TABLE dbo.mergetest (
mypartitioningcolumn date not null,
makemeunique int identity (1,1),
stuffnthings char(10) default ('stuff'),
thingsnstuff char(10) default ('things')
) on ps_mergethis(mypartitioningcolumn);
GO
CREATE UNIQUE CLUSTERED INDEX cx_mergetest on dbo.mergetest(mypartitioningcolumn, makemeunique);
GO
insert dbo.mergetest (mypartitioningcolumn) values ('2016-02-01');
GO 20
insert dbo.mergetest (mypartitioningcolumn) values ('2016-03-01');
GO 30
insert dbo.mergetest (mypartitioningcolumn) values ('2016-04-01');
GO 40
insert dbo.mergetest (mypartitioningcolumn) values ('2016-05-01');
GO 50
insert dbo.mergetest (mypartitioningcolumn) values ('2016-06-01');
GO 60
insert dbo.mergetest (mypartitioningcolumn) values ('2016-07-01');
GO 70
Where’s All Our Data? Let’s Query the Metadata
We inserted 20 rows for February 1, 30 rows for March 1, 40 rows for April 1, and so on. We can query how this is mapped to our filegroups:
SELECT
fg.name as fg_name,
pf.name as partition_function_name,
ps.name as partition_scheme_name,
pf.boundary_value_on_right,
p.partition_number,
prv.value as boundary_point,
so.name as table_name,
si.name as index_name,
stat.row_count,
stat.reserved_page_count * 8./1024./1024. as reserved_gb
FROM sys.indexes as si
JOIN sys.objects as so on si.object_id = so.object_id
JOIN sys.partitions as p on
si.object_id=p.object_id
and si.index_id=p.index_id
JOIN sys.data_spaces as ds on si.data_space_id = ds.data_space_id
JOIN sys.partition_schemes as ps on si.data_space_id=ps.data_space_id
JOIN sys.partition_functions AS pf on ps.function_id=pf.function_id
LEFT JOIN sys.allocation_units as au on p.hobt_id=au.container_id
LEFT JOIN sys.filegroups as fg on au.data_space_id=fg.data_space_id
LEFT JOIN sys.dm_db_partition_stats as stat on stat.object_id=p.object_id
and stat.index_id=p.index_id
and stat.index_id=p.index_id and stat.partition_id=p.partition_id
and stat.partition_number=p.partition_number
LEFT JOIN sys.partition_range_values as prv on prv.function_id=pf.function_id
and p.partition_number = prv.boundary_id + pf.boundary_value_on_right
WHERE ps.name='ps_mergethis'
GO
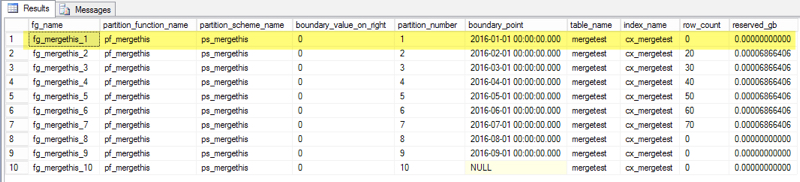
This all looks in order. We have a boundary point for January 1, but we didn’t insert any rows for it. It’s mapped to the fg_mergethis_1 filegroup and is currently partition_number 1.
And Now We Merge
The question I got was about merging, so let’s merge! We’re going to get rid of the January 1 Boundary Point:
ALTER PARTITION FUNCTION pf_mergethis () MERGE RANGE ('2016-01-01');
GO
Blammo, it’s gone!
Rerunning our query for the metadata above, here’s what the table looks like now:
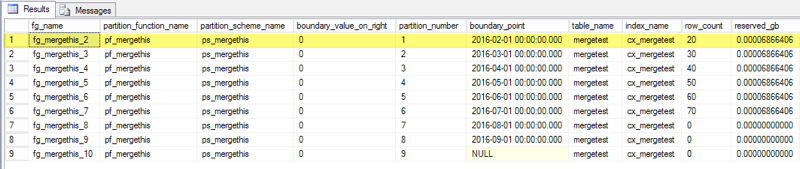
We blew away a partition – the partition mapped to fg_mergethis_1 is now totally gone. Partition_number 1 has been reassigned to the partition with a boundary point of February 1.
But data didn’t move when we merged the partitions in this case. There were always 20 rows in the fg_mergethis_2 filegroup.
Partition_number is a logical construct. When it changes you don’t necessarily have a data movement.
Data Movement Matters – It Can Be Seriously Slow
It’s completely valid to be concerned about data movement. “Data movement” is just what it sounds like: data being physically moved from one partition to another. It’s fully logged and can cause a huge performance hit. If you’re planning out partitioning, you need to carefully:
- Decide if you’re using left or right for your partition function
- Decide how many filegroups you’re using (it’s relevant to merge performance!)
- Test out split and merge if you’re using them and examine carefully if you’re getting data movement. If you’re getting data movement, re-read the section on MERGE RANGE in the documentation for ALTER PARTITION FUNCTION and revisit your design.
- Test out partition elimination for your queries and make sure it behaves like you expect (if not, revisit your choices)
Do You Even Need to Merge?
When you’re designing partitioning, it’s always worth thinking about whether a rotating log design could work for you.
Avoiding merge and split makes life easier in the long run if possible, so don’t forget this architecture when you’re in the design phase.